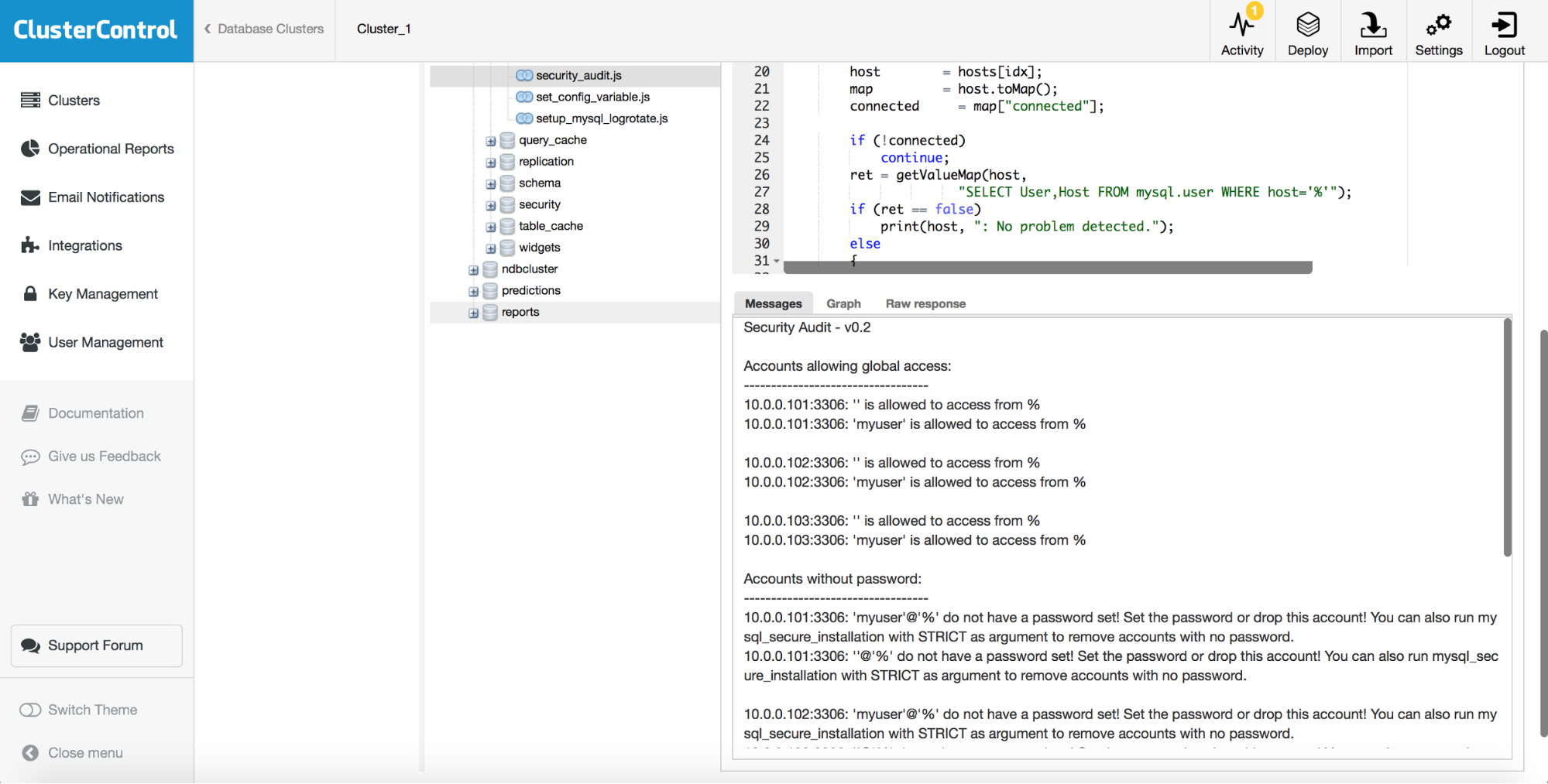
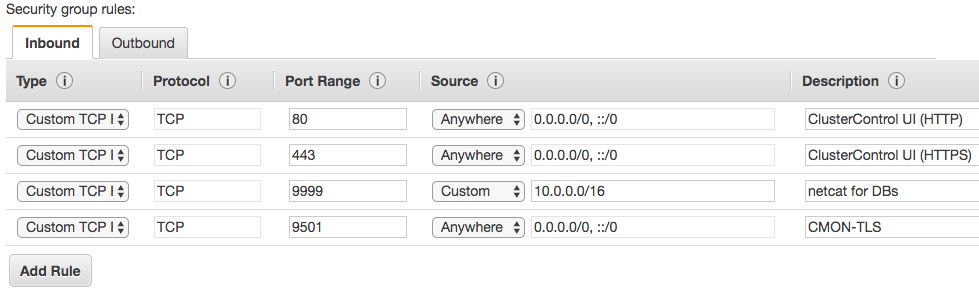
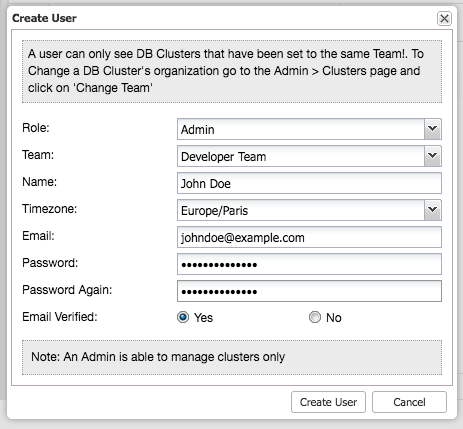
A proxy layer can be quite useful in increasing availability of your database tier. It may reduce the amount of code on the application side to handle database failures and replication topology changes. In this blog post we will discuss how to setup a HAProxy to work on top of PostgreSQL.
First things first - HAProxy works with databases as a network layer proxy. There is no understanding of the underlying, sometimes complex, topology. All HAProxy does is to send packets in round-robin fashion to defined backends. It does not inspect packets nor it understands protocol in which applications talk with PostgreSQL. As a result, there’s no way for the HAProxy to implement read/write split on a single port - it would require parsing of queries. As long as your application can split reads from writes and send them to different IPs or ports, you can implement R/W split using two backends. Let’s take a look at how it can be done.
HAProxy Configuration
Below you can find an example of two PostgreSQL backends configured in HAProxy.
listen haproxy_10.0.0.101_3307_rw
bind *:3307
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string master\ is\ running
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 check
listen haproxy_10.0.0.101_3308_ro
bind *:3308
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running.
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 checkAs we can see, they use ports 3307 for writes and 3308 for reads. In this setup there are three servers - one active and two standby replicas. What’s important, tcp-check is used to track the health of the nodes. HAProxy will connect to port 9201 and it expects to see a string returned. Healthy members of the backend will return expected content, those who will not return the string will be marked as unavailable.
Xinetd Setup
As HAProxy checks port 9201, something has to listen on it. We can use xinetd to listen there and run some scripts for us. Example configuration of such service may look like:
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITED
}You need to make sure you add the line:
postgreschk 9201/tcpto the /etc/services.
Xinetd starts a postgreschk script, which has contents like below:
#!/bin/bash
#
# This script checks if a PostgreSQL server is healthy running on localhost. It will
# return:
# "HTTP/1.x 200 OK\r" (if postgres is running smoothly)
# - OR -
# "HTTP/1.x 500 Internal Server Error\r" (else)
#
# The purpose of this script is make haproxy capable of monitoring PostgreSQL properly
#
export PGHOST='10.0.0.101'
export PGUSER='someuser'
export PGPASSWORD='somepassword'
export PGPORT='5432'
export PGDATABASE='postgres'
export PGCONNECT_TIMEOUT=10
FORCE_FAIL="/dev/shm/proxyoff"
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"
return_ok()
{
echo -e "HTTP/1.1 200 OK\r\n"
echo -e "Content-Type: text/html\r\n"
if [ "$1x" == "masterx" ]; then
echo -e "Content-Length: 56\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL master is running.</body></html>\r\n"
elif [ "$1x" == "slavex" ]; then
echo -e "Content-Length: 55\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL slave is running.</body></html>\r\n"
else
echo -e "Content-Length: 49\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is running.</body></html>\r\n"
fi
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 0
}
return_fail()
{
echo -e "HTTP/1.1 503 Service Unavailable\r\n"
echo -e "Content-Type: text/html\r\n"
echo -e "Content-Length: 48\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is *down*.</body></html>\r\n"
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 1
}
if [ -f "$FORCE_FAIL" ]; then
return_fail;
fi
# check if in recovery mode (that means it is a 'slave')
SLAVE=$(psql -qt -c "$SLAVE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $SLAVE | egrep -i "(t|true|on|1)" 2>/dev/null >/dev/null; then
return_ok "slave"
fi
# check if writable (then we consider it as a 'master')
READONLY=$(psql -qt -c "$WRITABLE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $READONLY | egrep -i "(f|false|off|0)" 2>/dev/null >/dev/null; then
return_ok "master"
fi
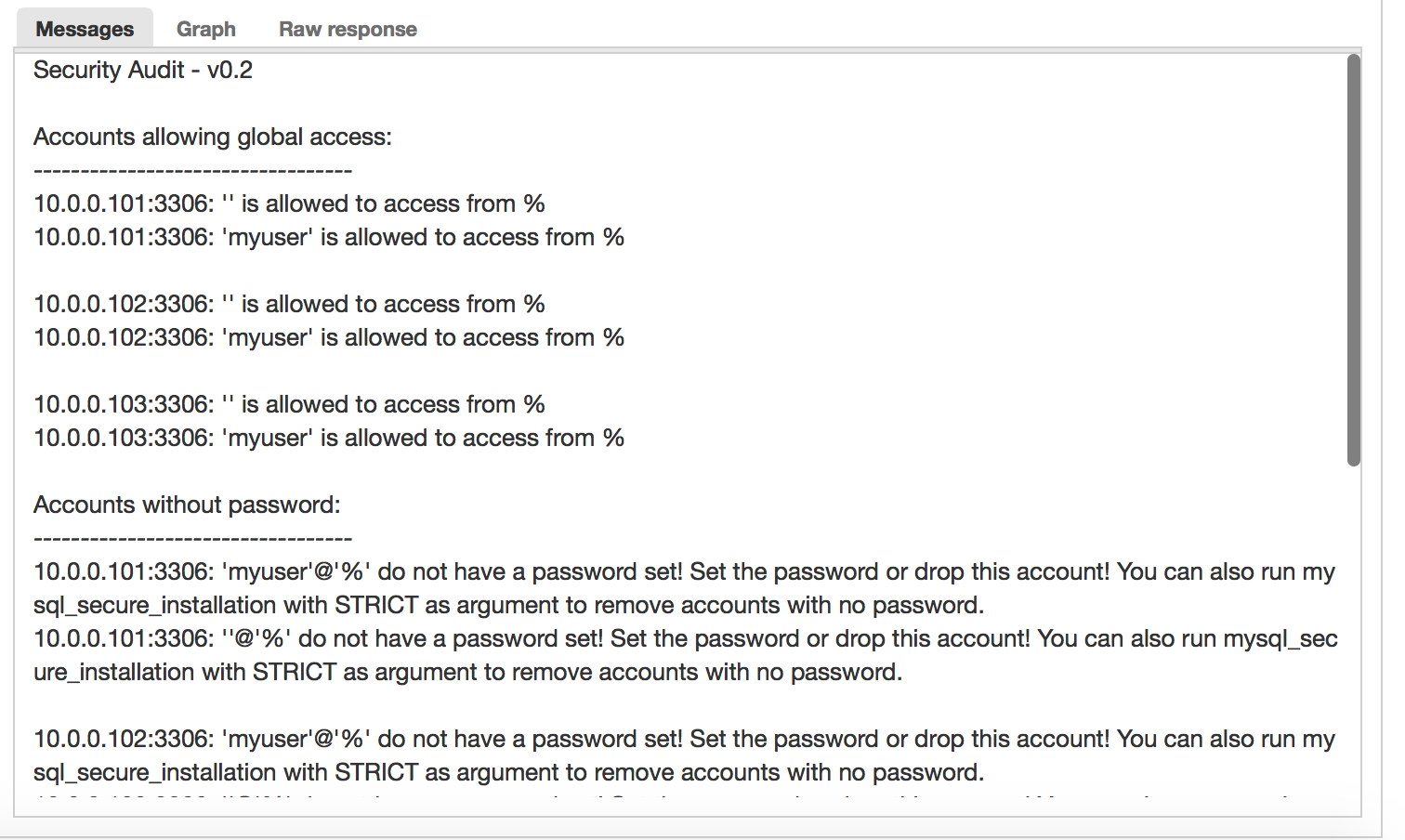
return_ok "none";The logic of the script goes as follows. There are two queries which are used to detect the state of the node.
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"The first checks if PostgreSQL is in recovery - it will be ‘false’ for the active server and ‘true’ for standby servers. The second checks if PostgreSQL is in read-only mode. The active server will return ‘off’ while standby servers will return ‘on’. Based on the results, the script calls the return_ok() function with a right parameter (‘master’ or ‘slave’, depending on what was detected). If the queries failed, a ‘return_fail’ function will be executed.
Return_ok function returns a string based on the argument which was passed to it. If the host is an active server, the script will return “PostgreSQL master is running”. If it is a standby, the returned string will be: “PostgreSQL slave is running”. If the state is not clear, it’ll return: “PostgreSQL is running”. This is where the loop ends. HAProxy checks the state by connecting to xinetd. The latter starts a script, which then returns a string that HAProxy parses.
As you may remember, HAProxy expects the following strings:
tcp-check expect string master\ is\ runningfor the write backend and
tcp-check expect string is\ running.for the read-only backend. This makes the active server the only host available in the write backend while on the read backend, both active and standby servers can be used.
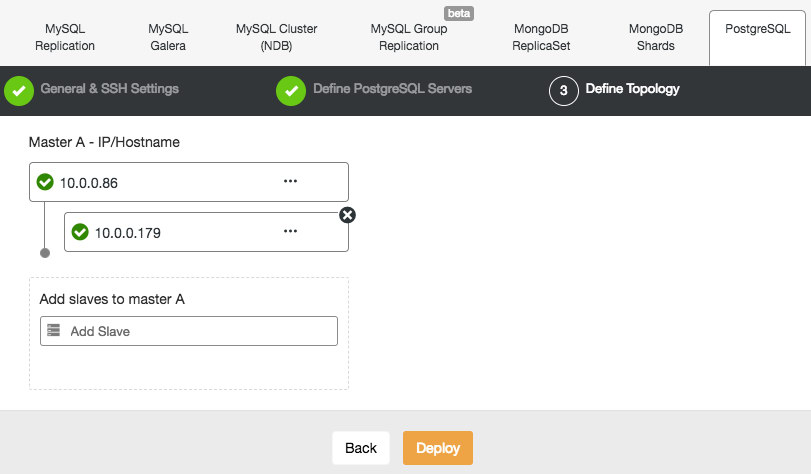
PostgreSQL and HAProxy in ClusterControl
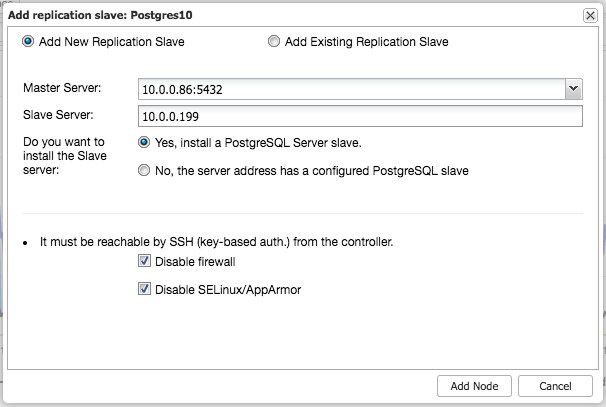
The setup above is not complex, but it does takes some time to set it up. ClusterControl can be used to set all of this up for you.
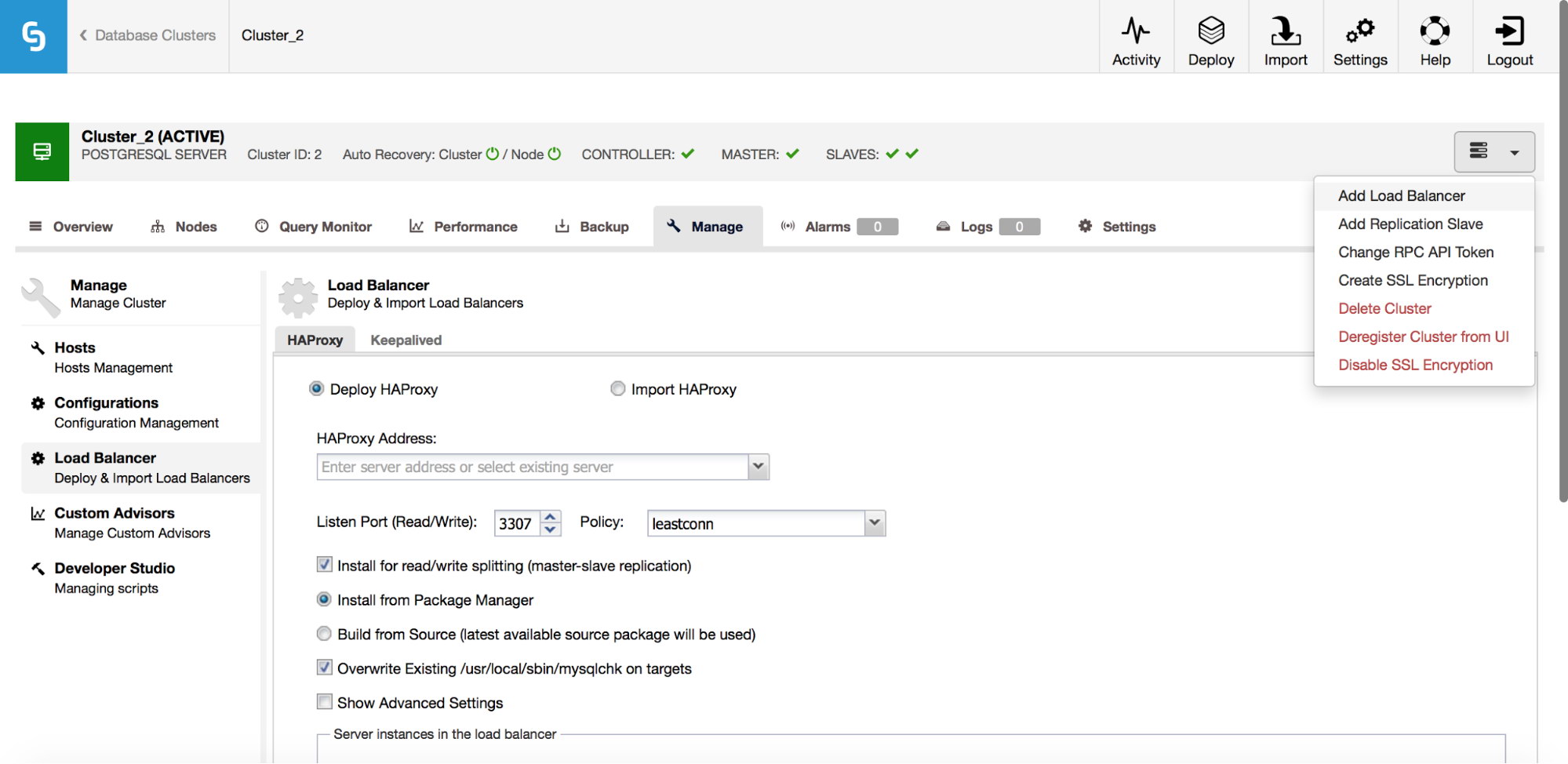
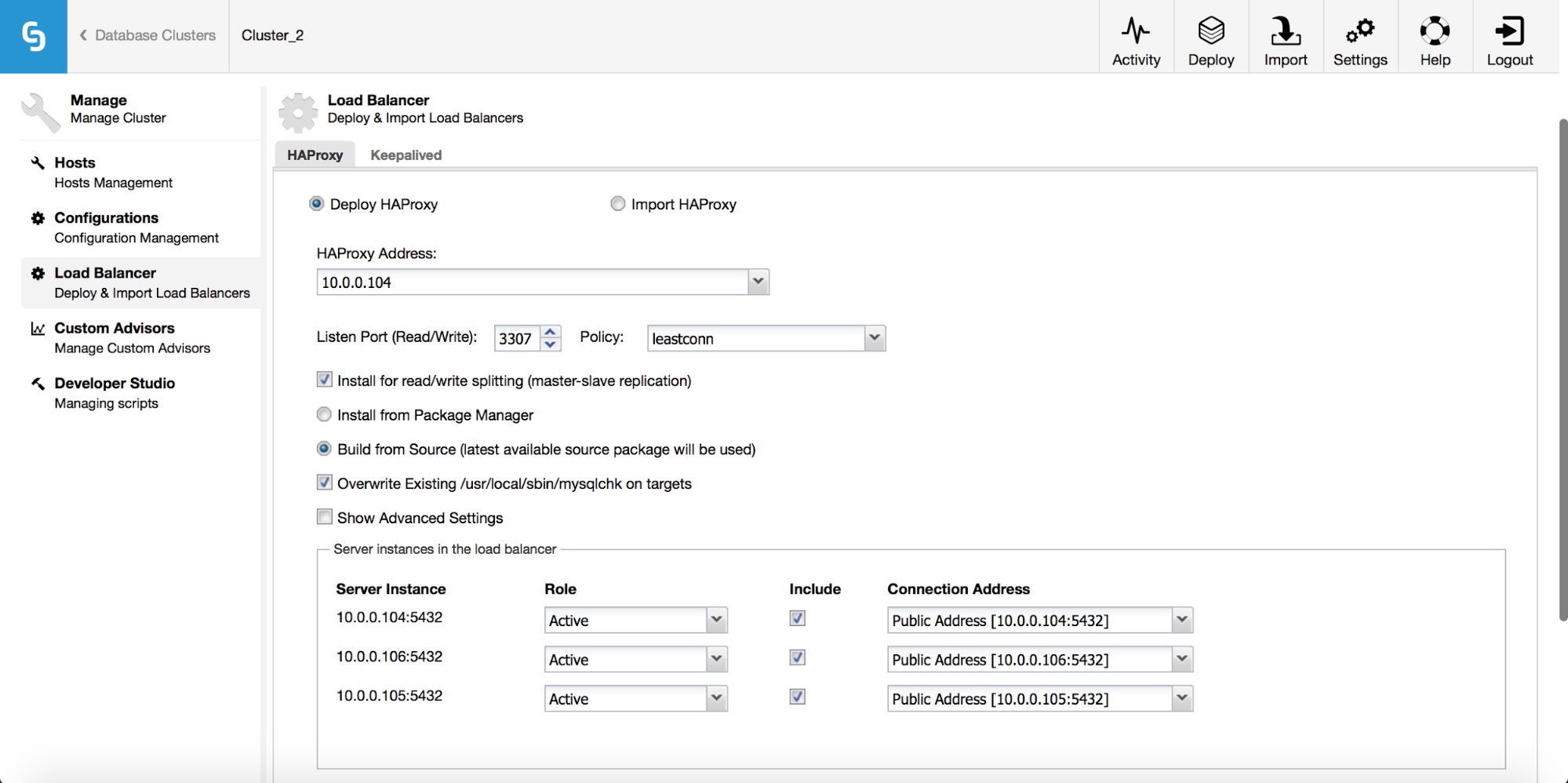
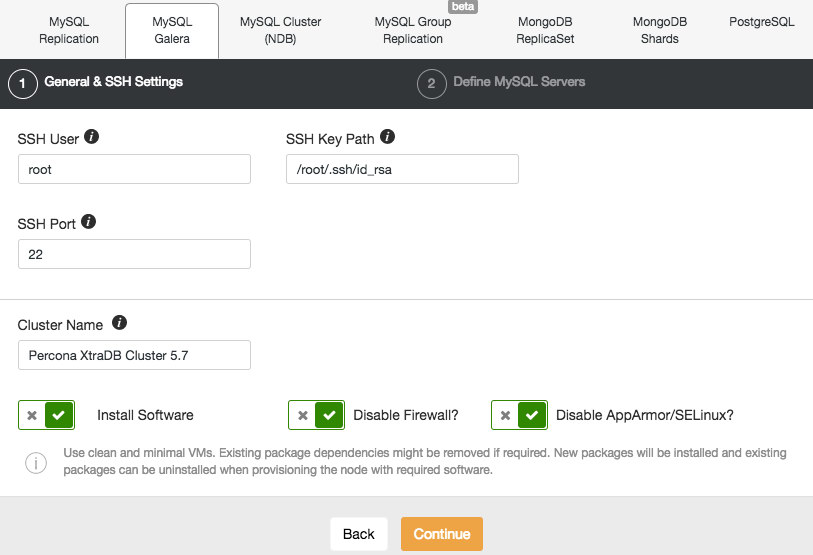
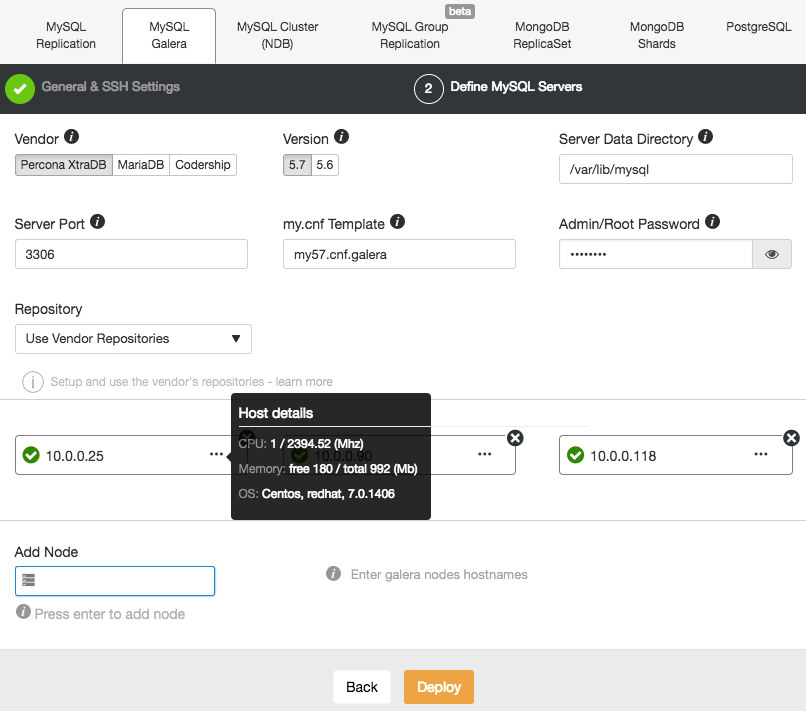
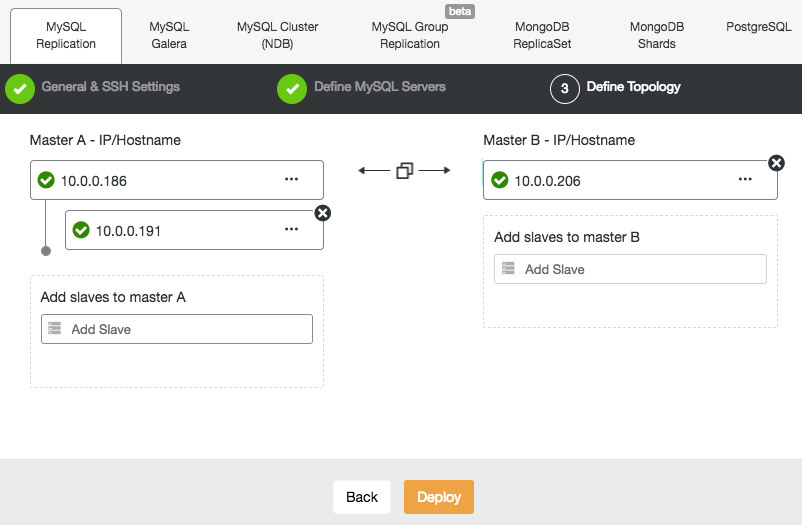
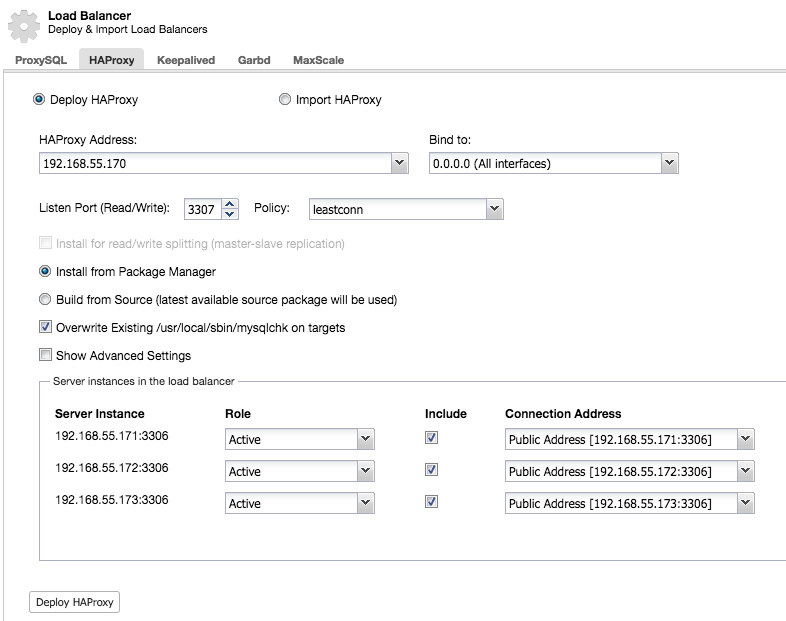
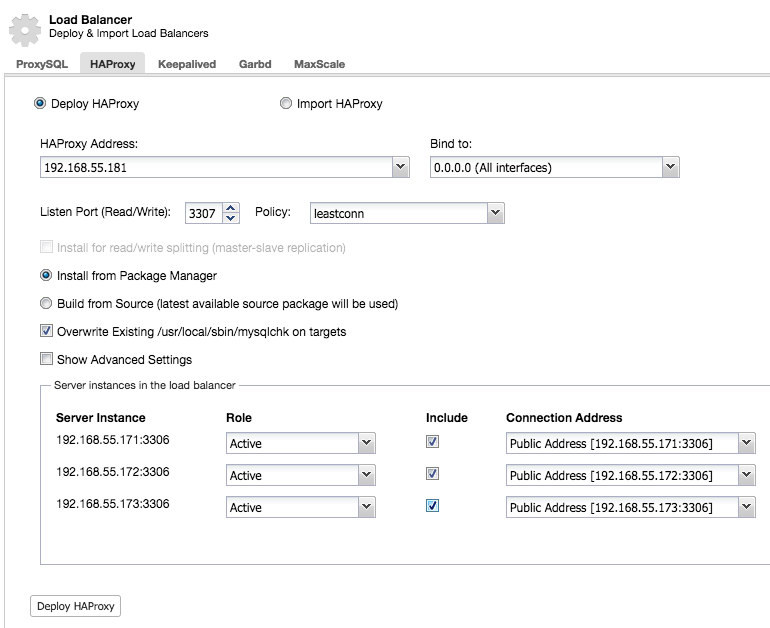
In the cluster job dropdown menu, you have an option to add a load balancer. Then an option to deploy HAProxy shows up. You need to fill in where you’d like to install it, and make some decisions: from the repositories that you have configured on the host or the latest version, compiled from the source code. You’ll also need to configure which nodes in the cluster you’d like to add to HAProxy.
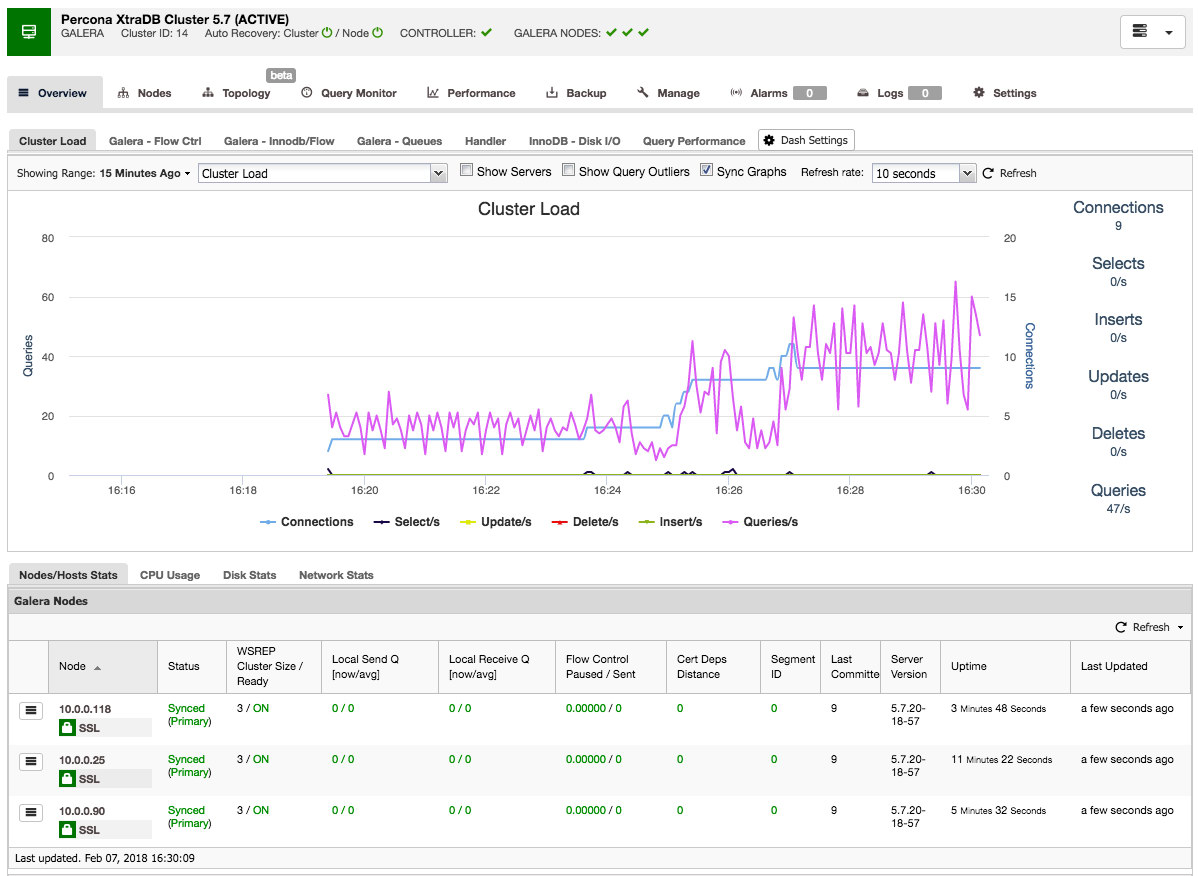
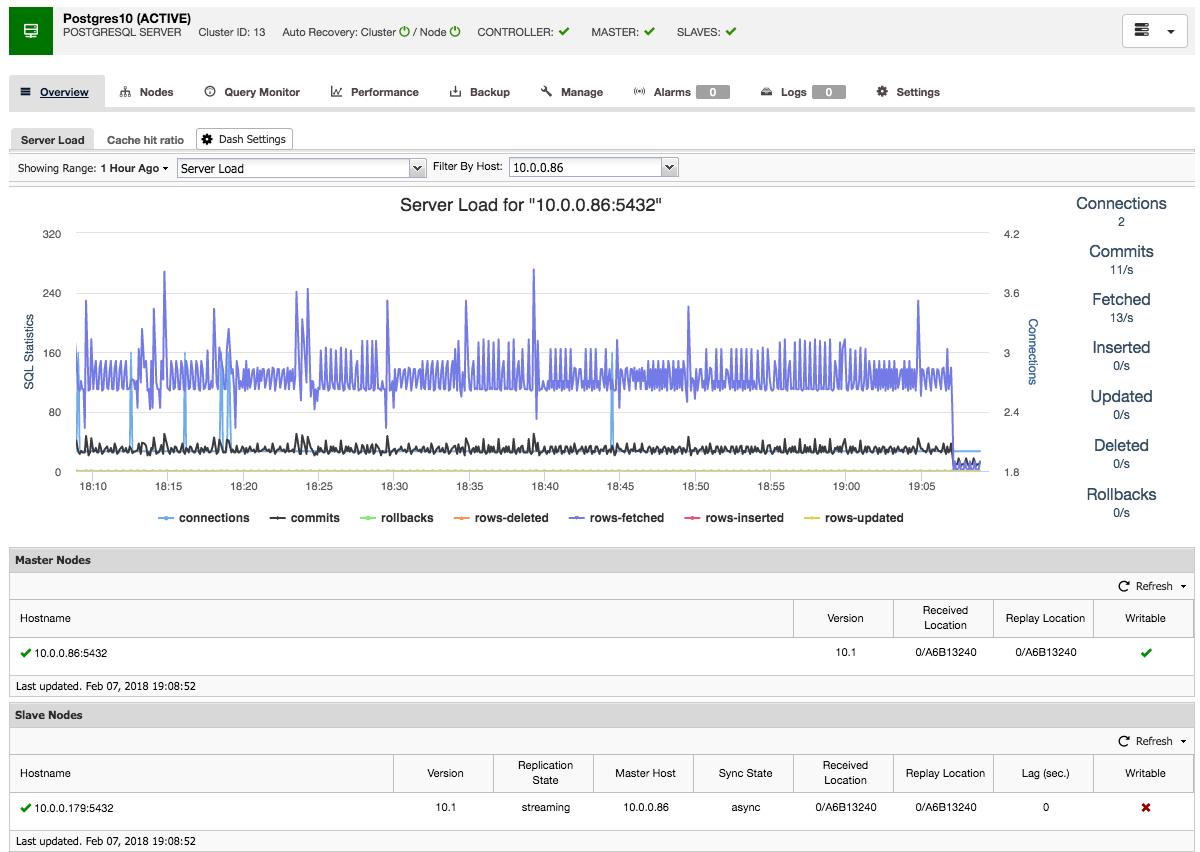
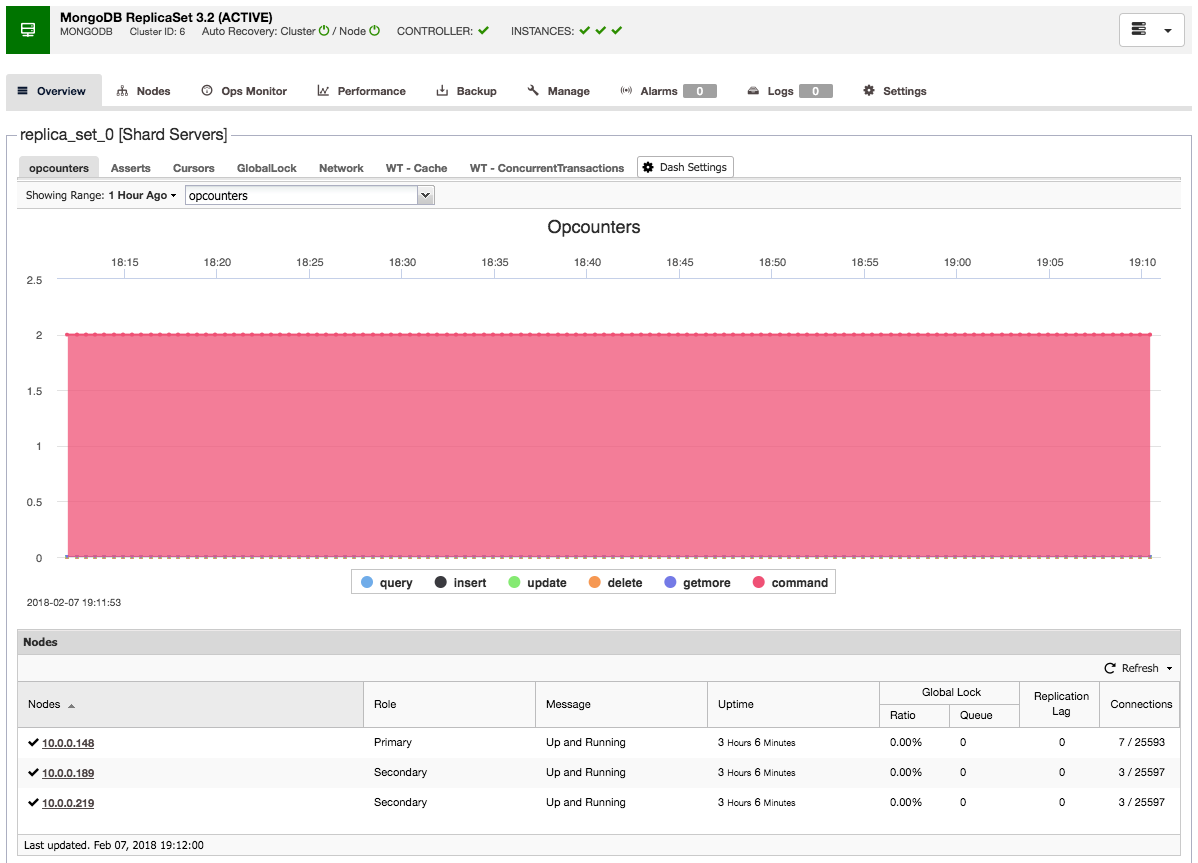
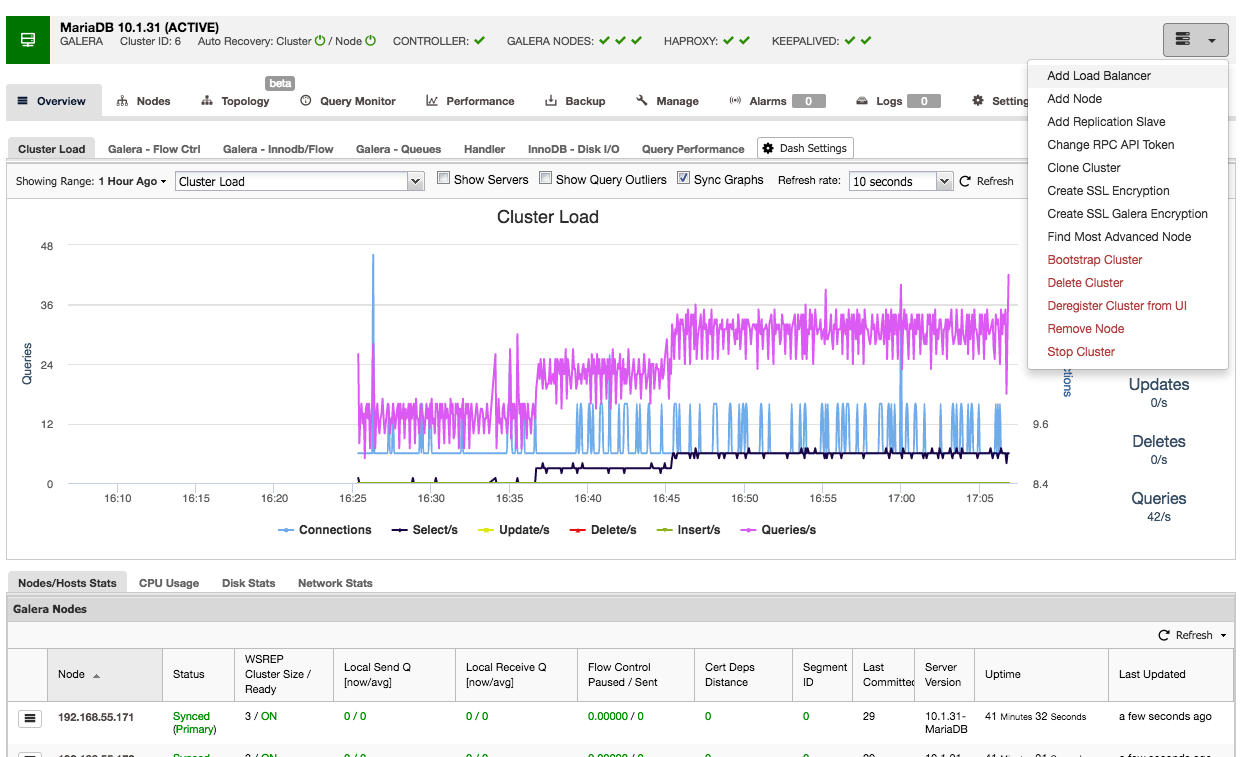
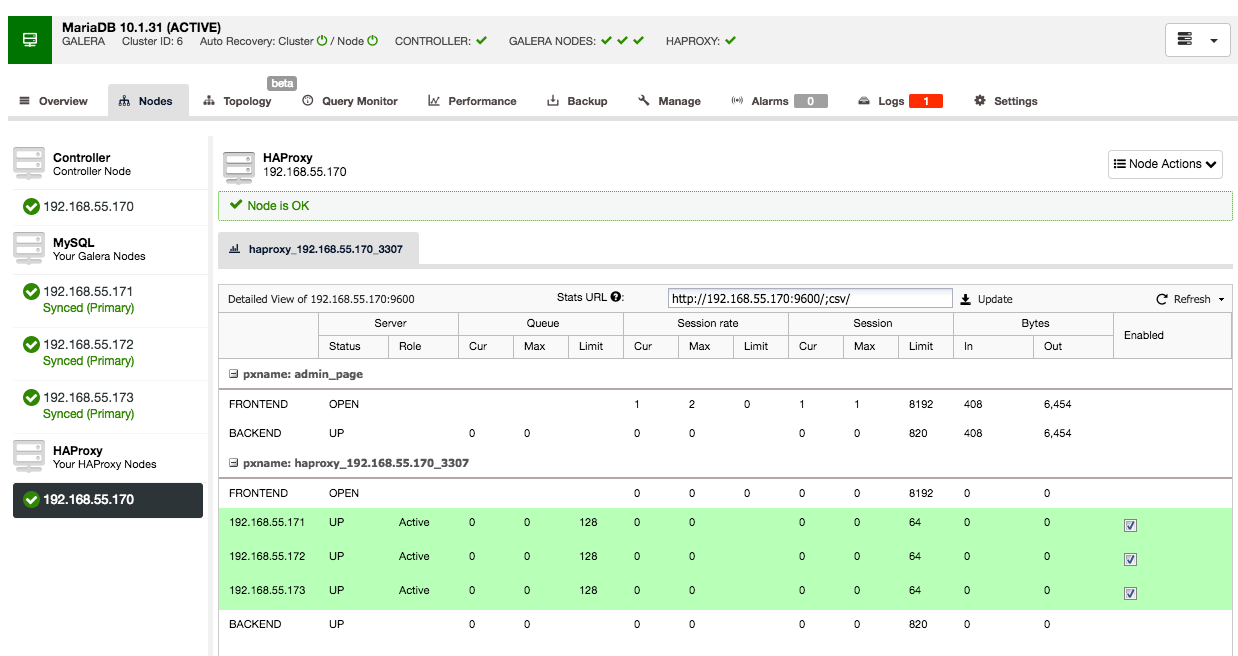
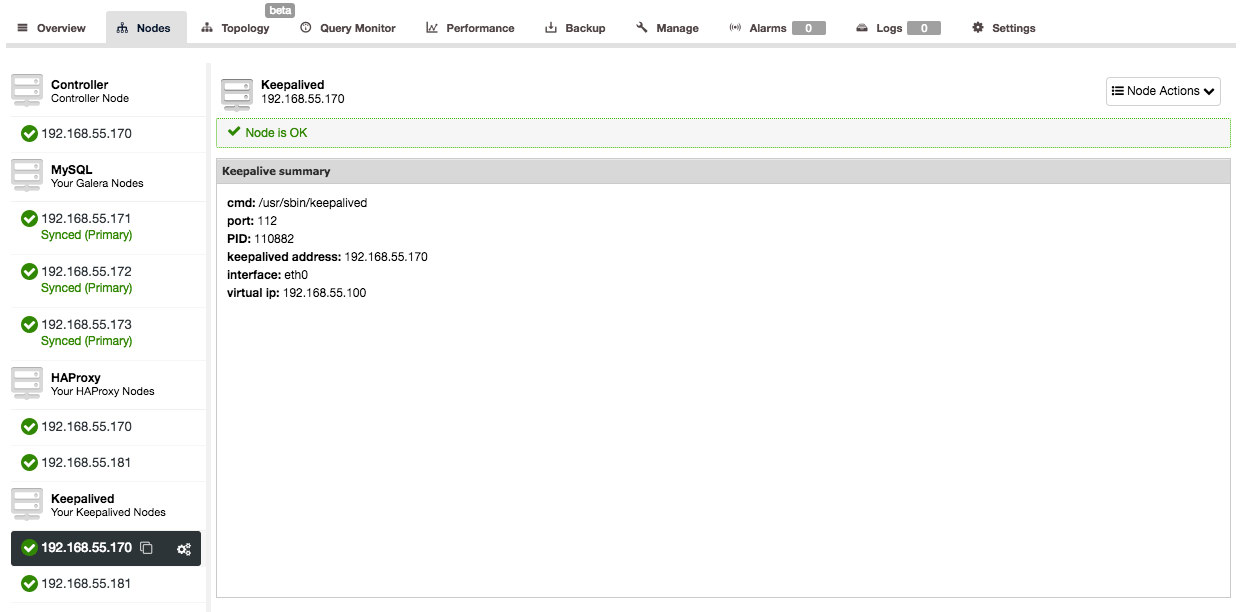
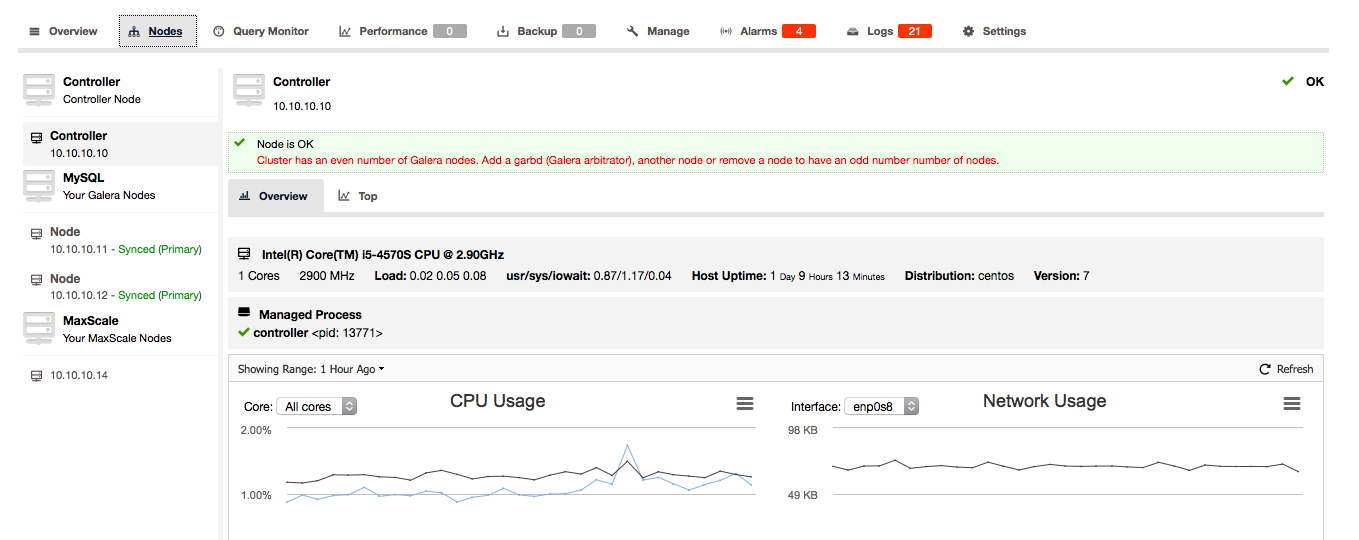
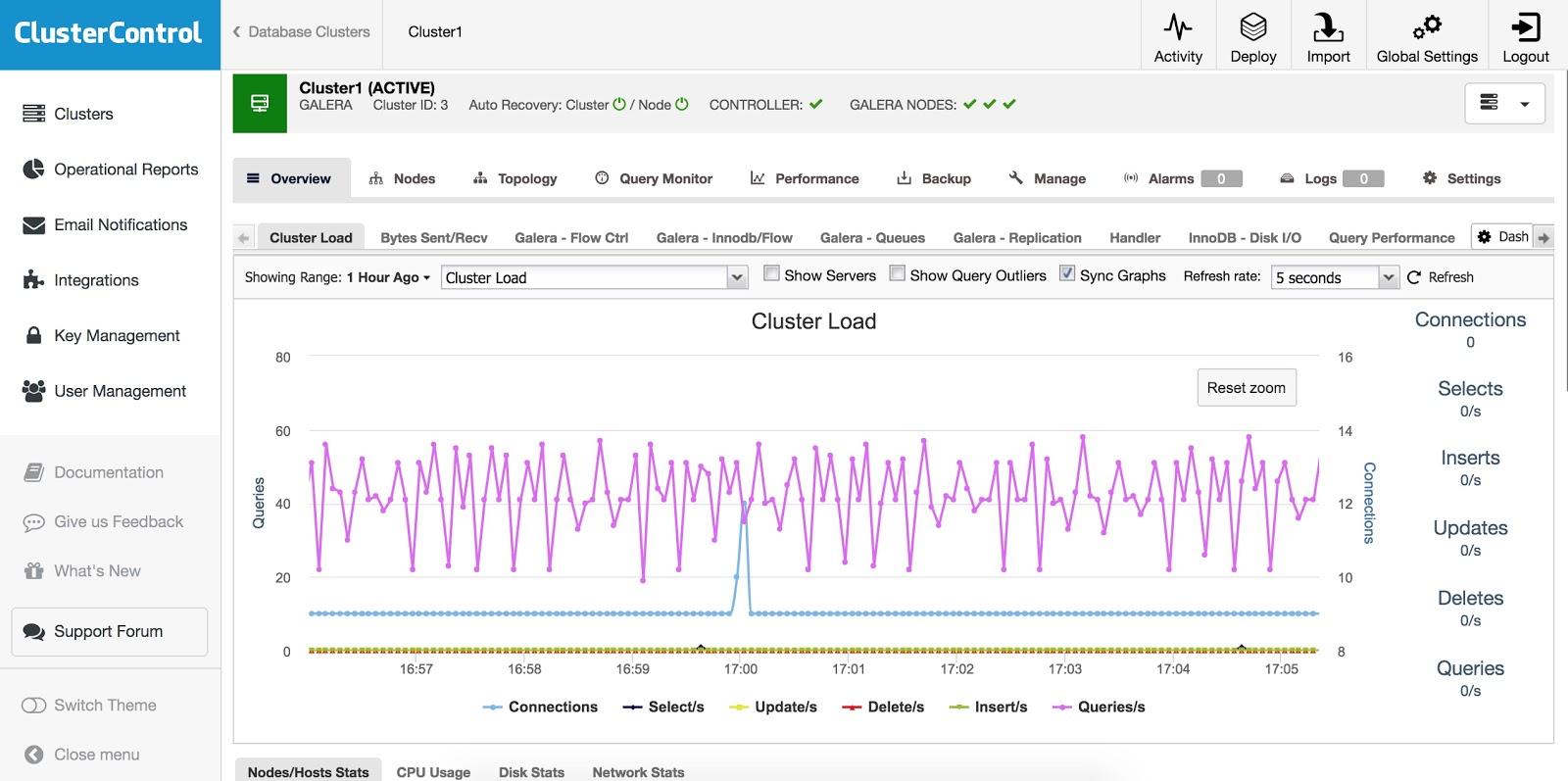
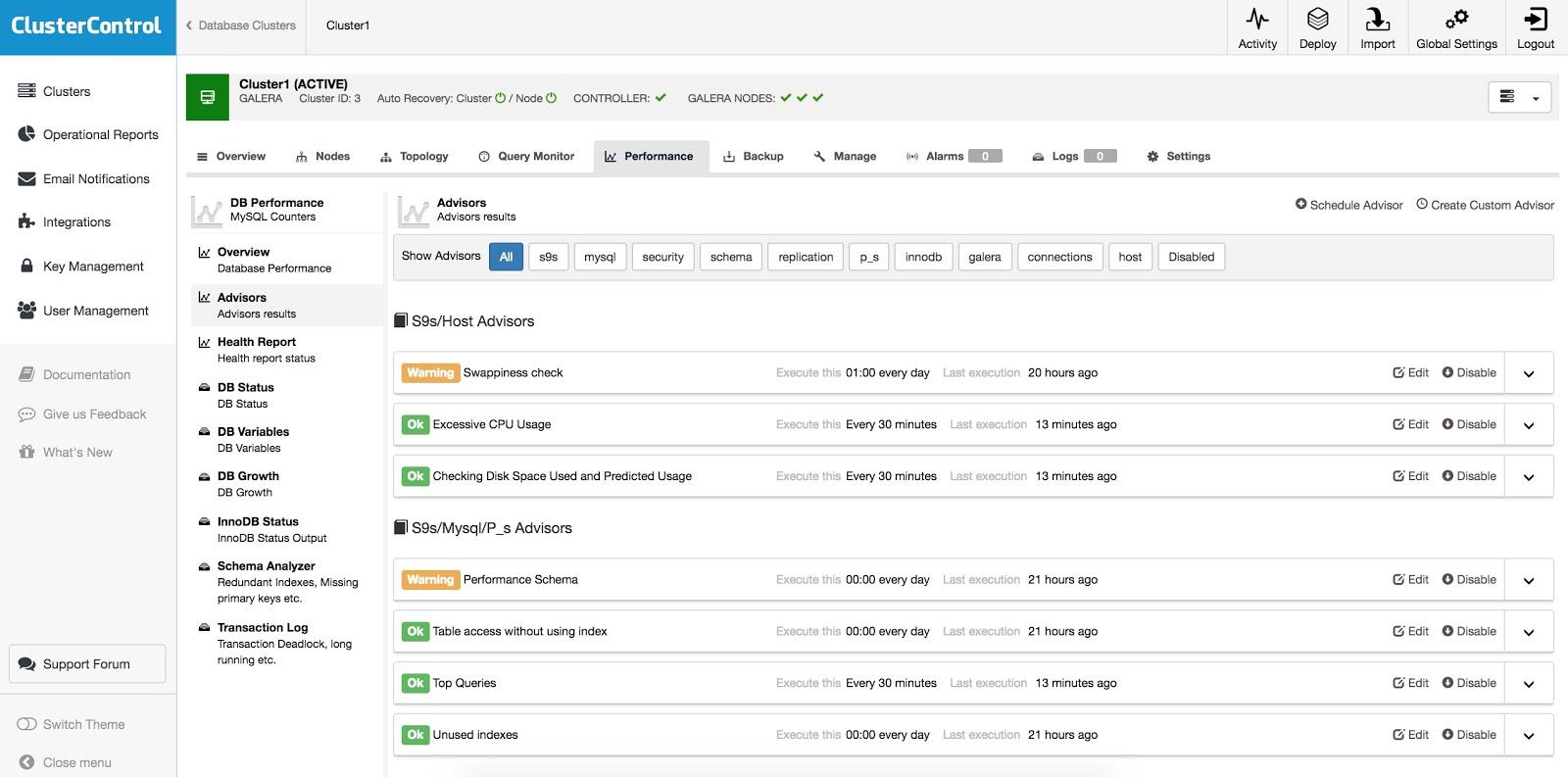
Once the HAProxy instance is deployed, you can access some statistics in the “Nodes” tab:
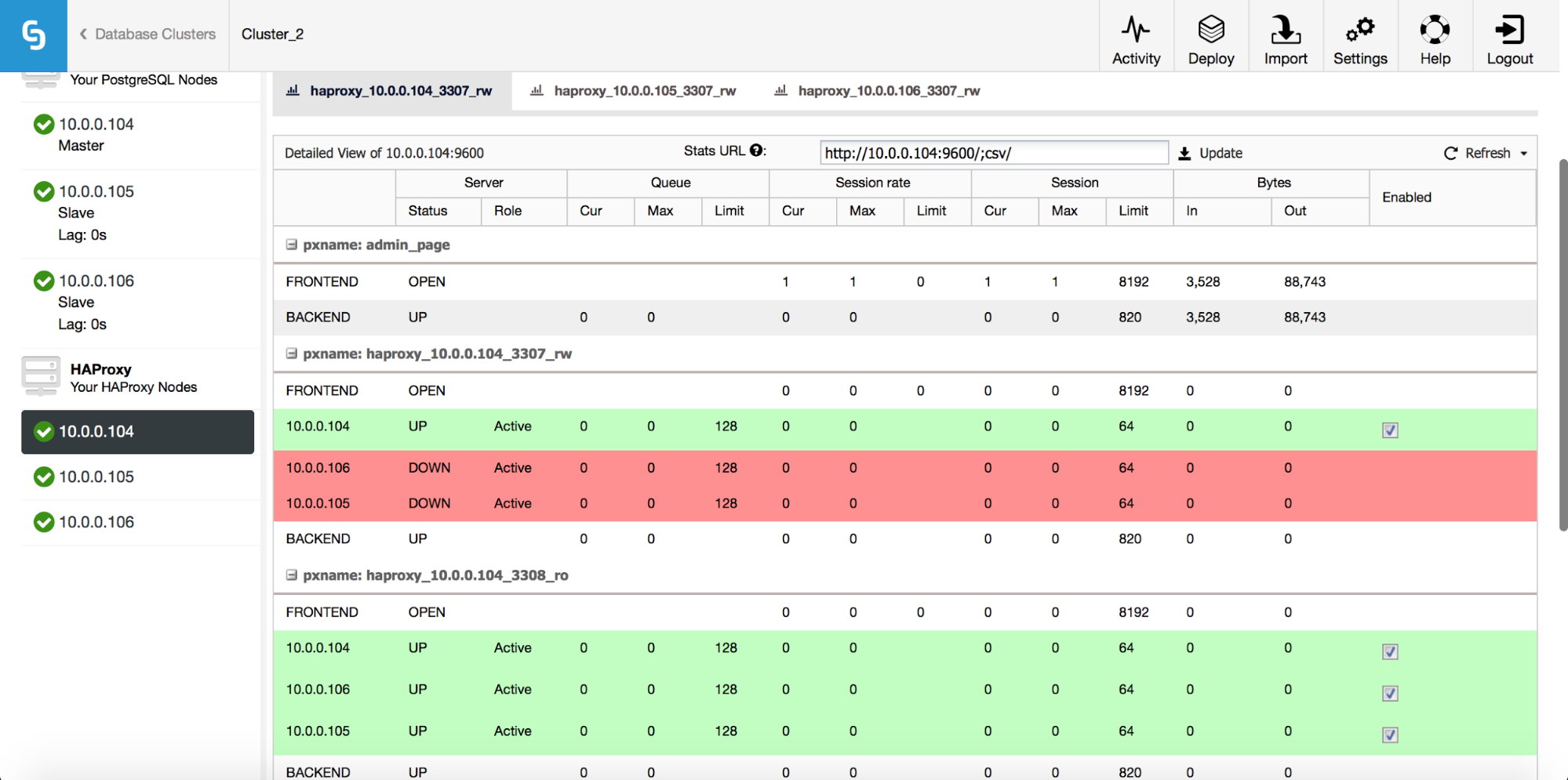
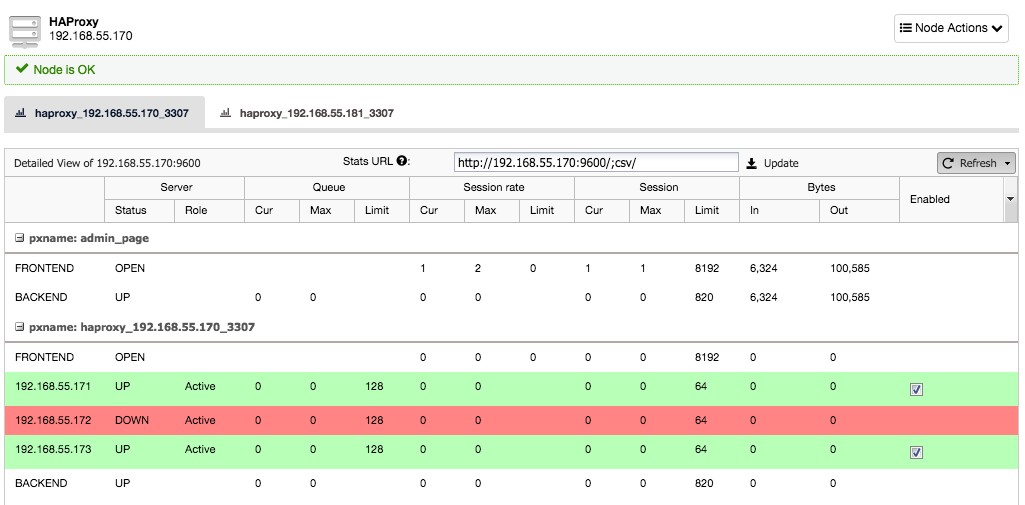
As we can see, for the R/W backend, only one host (active server) is marked as up. For the read-only backend, all nodes are up.
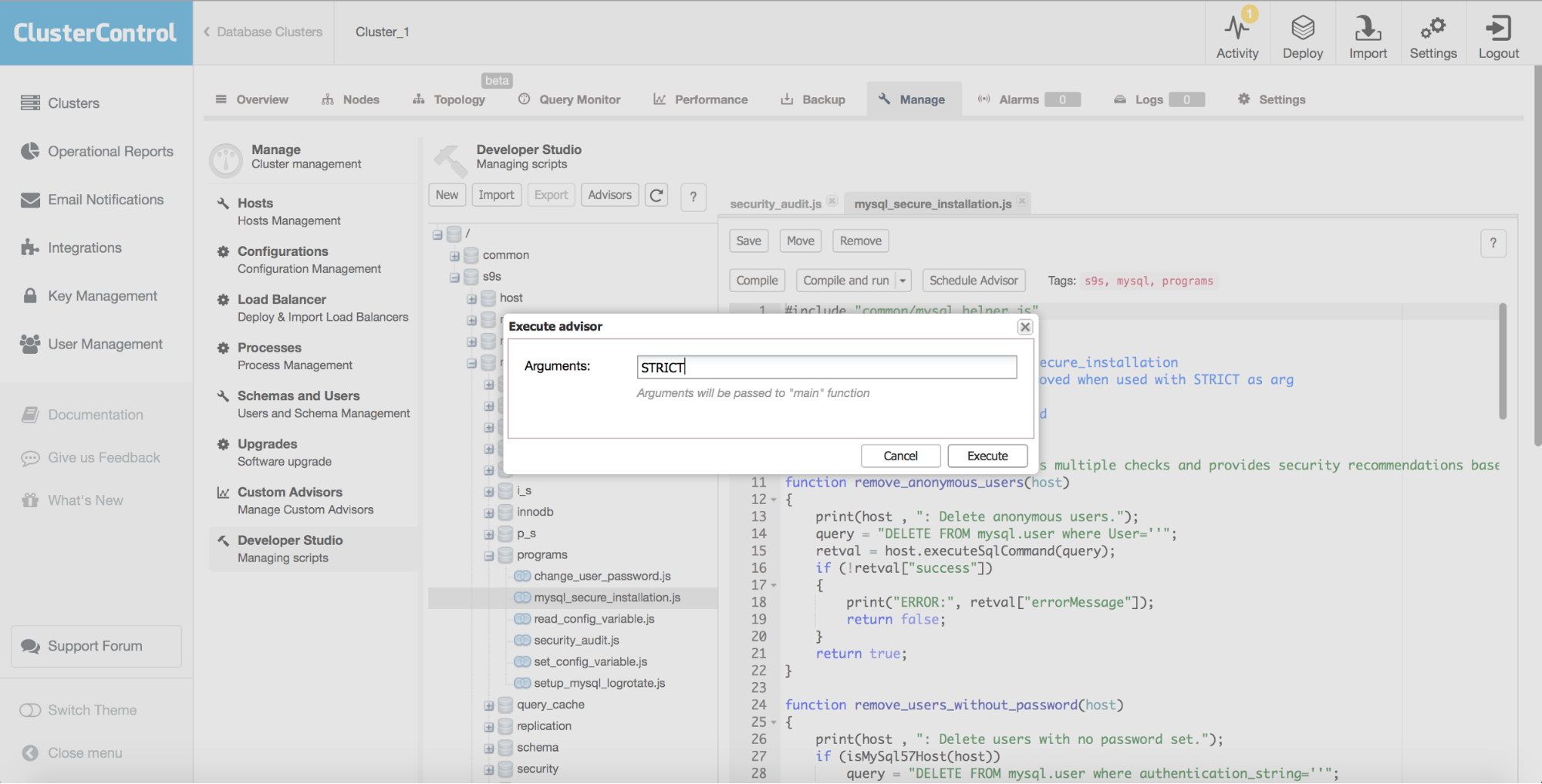
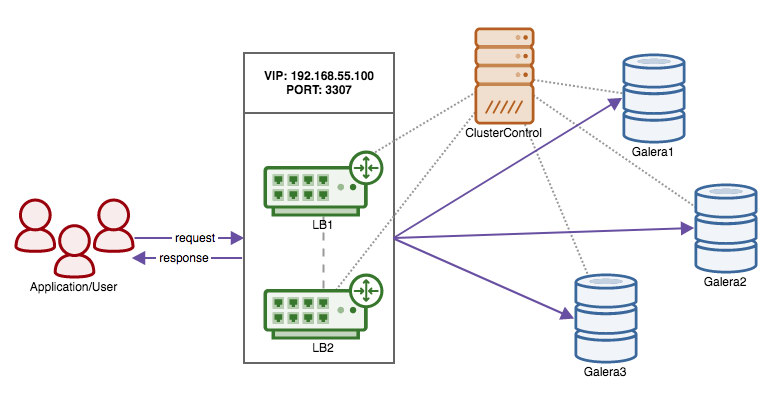
Keepalived
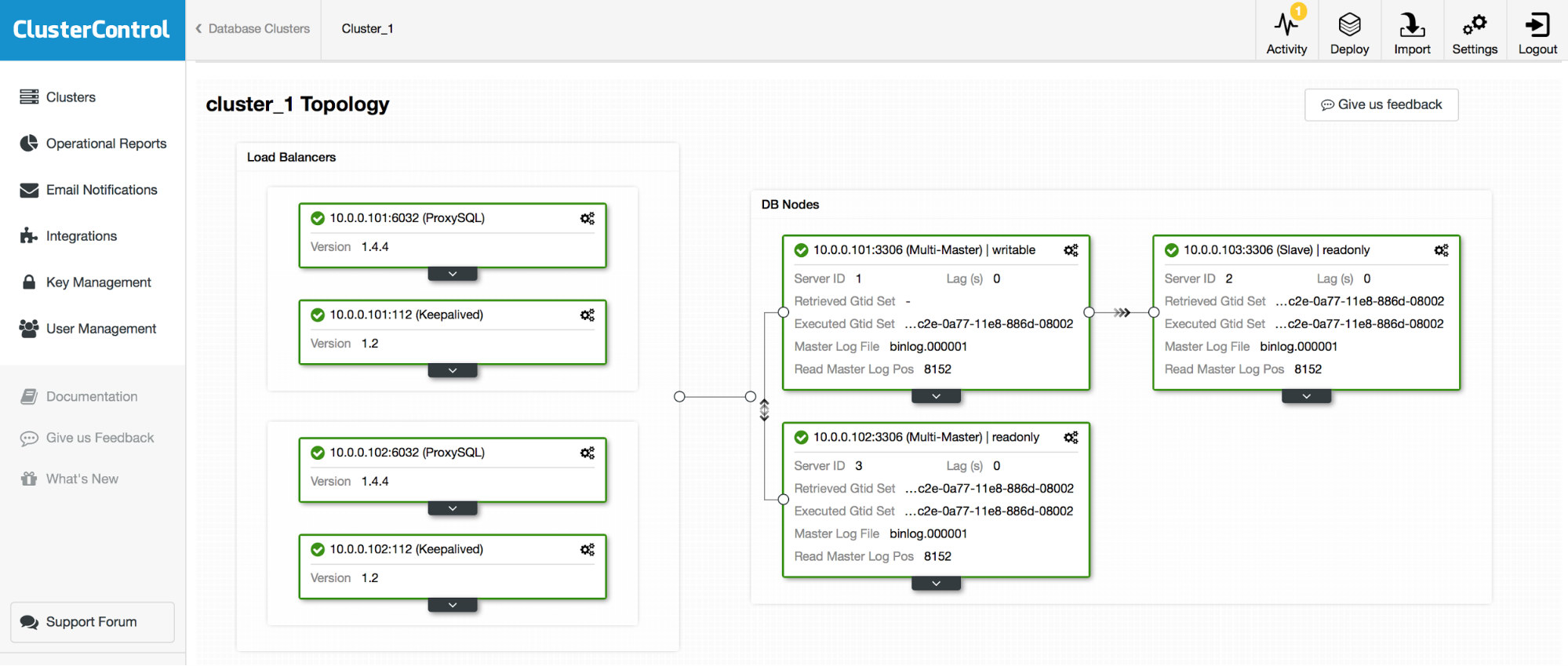
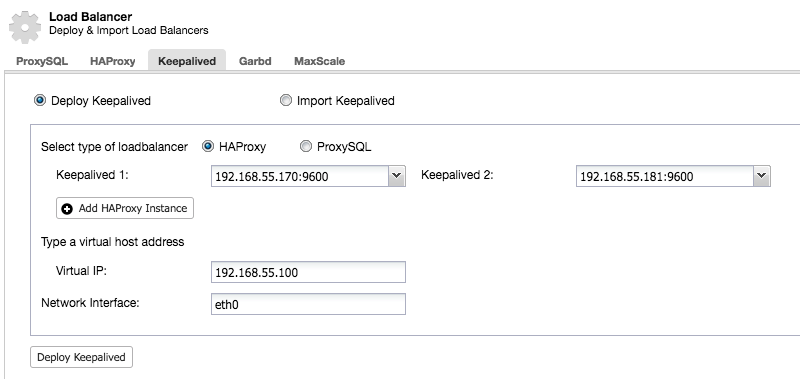
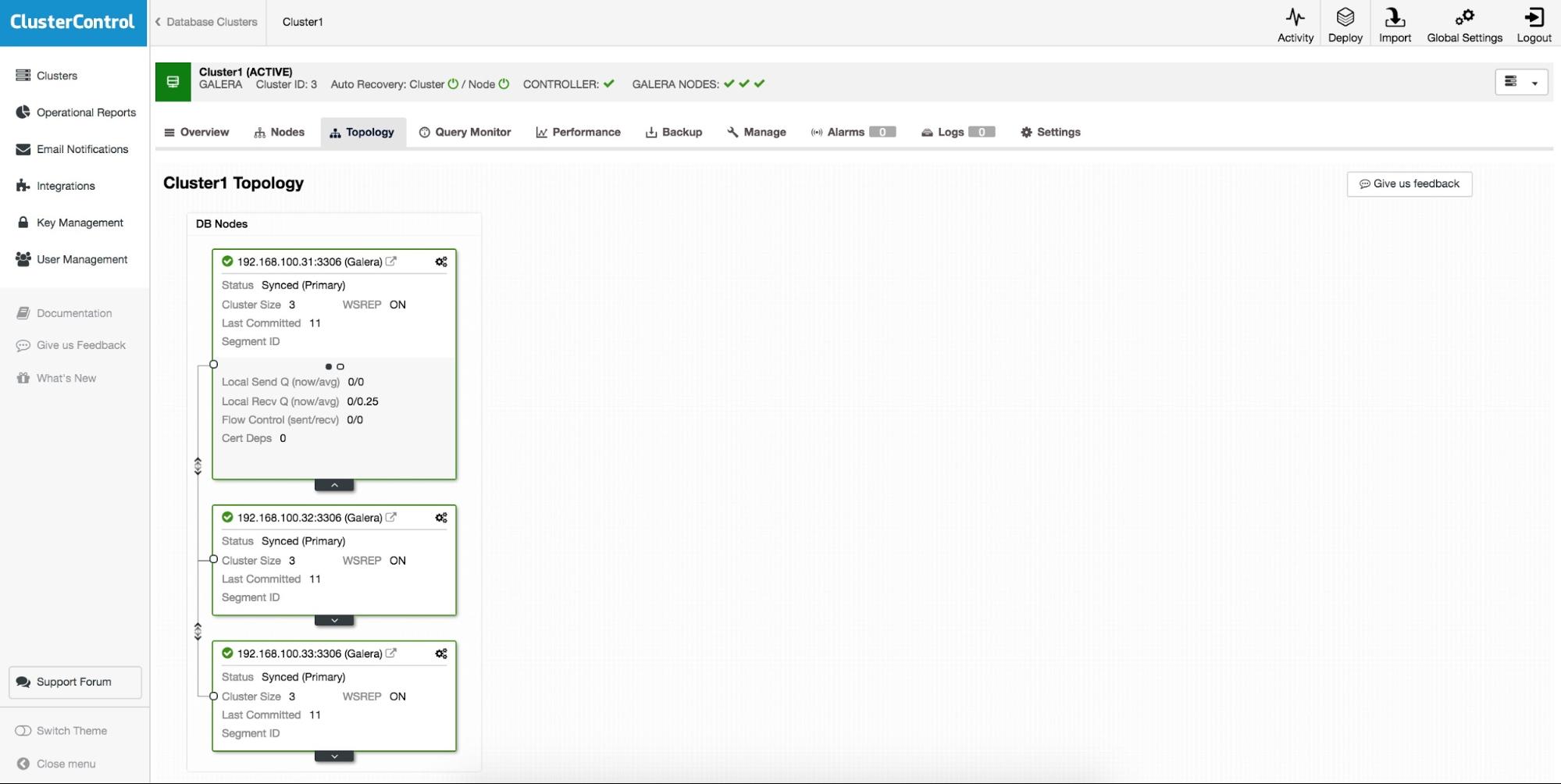
HAProxy will sit between your applications and database instances, so it will be playing a central role. It can unfortunately also become a single point of failure, should it fail, there will be no route to the databases. To avoid such a situation, you can deploy multiple HAProxy instances. But then the question is - how to decide to which proxy host to connect to. If you deployed HAProxy from ClusterControl, it’s as simple as running another “Add Load Balancer” job, this time deploying Keepalived.
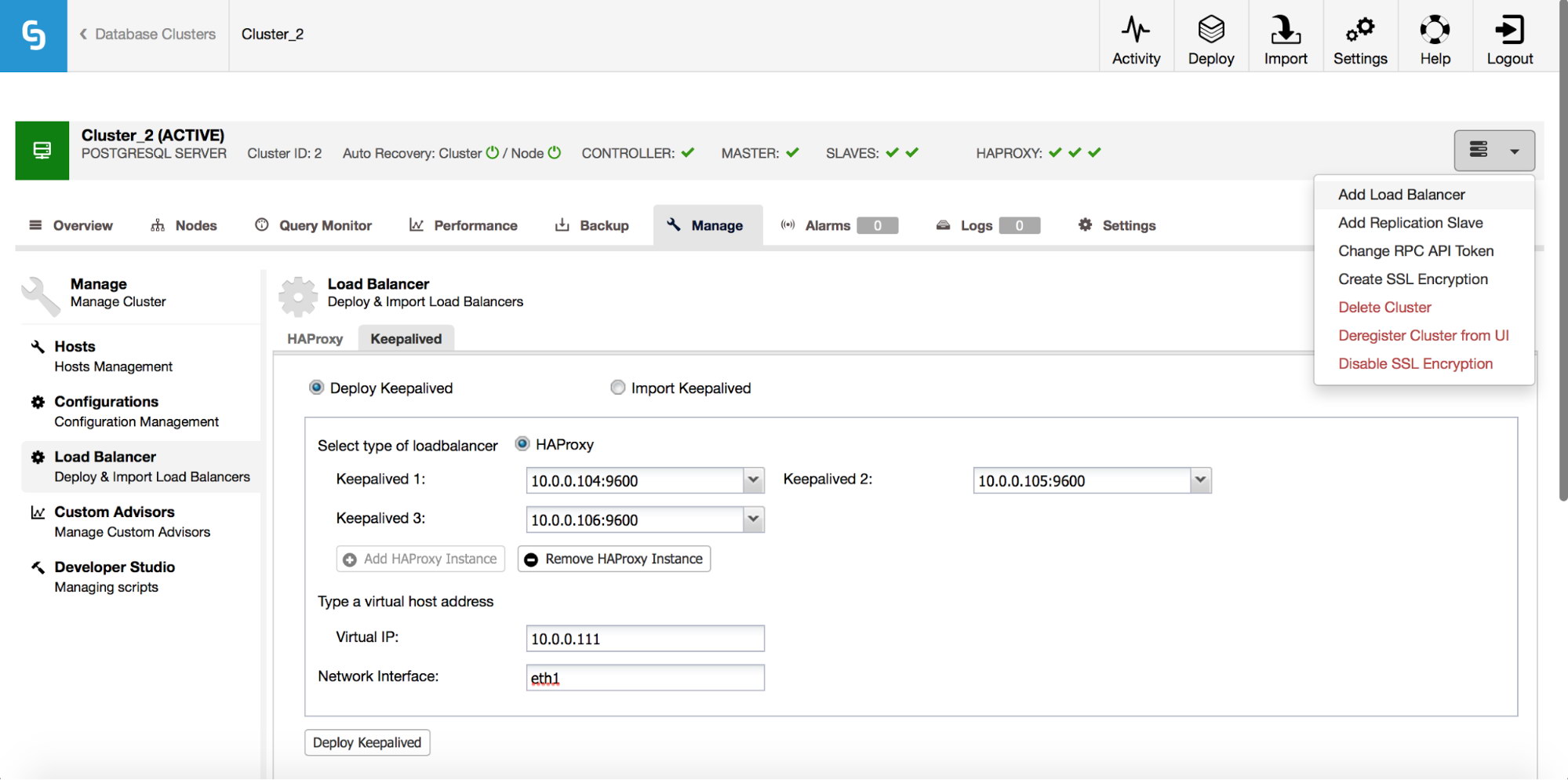
As we can see in the screenshot above, you can pick up to three HAProxy hosts and Keepalived will be deployed on top of them, monitoring their state. A Virtual IP (VIP) will be assigned to one of them. Your application should use this VIP to connect to the database. If the “active” HAProxy will become unavailable, VIP will be moved to another host.
As we have seen, it’s quite easy to deploy a full high availability stack for PostgreSQL. Do give it a try and let us know if you have any feedback.