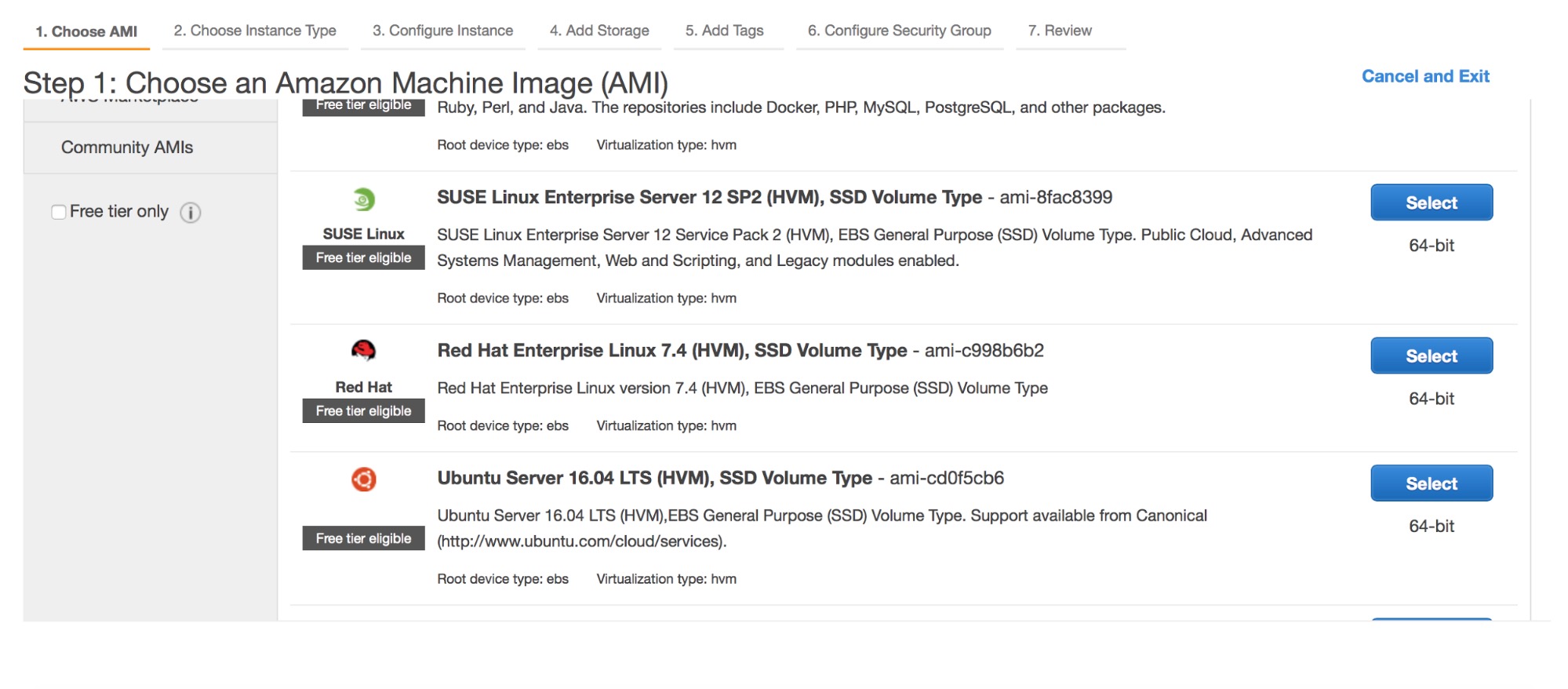
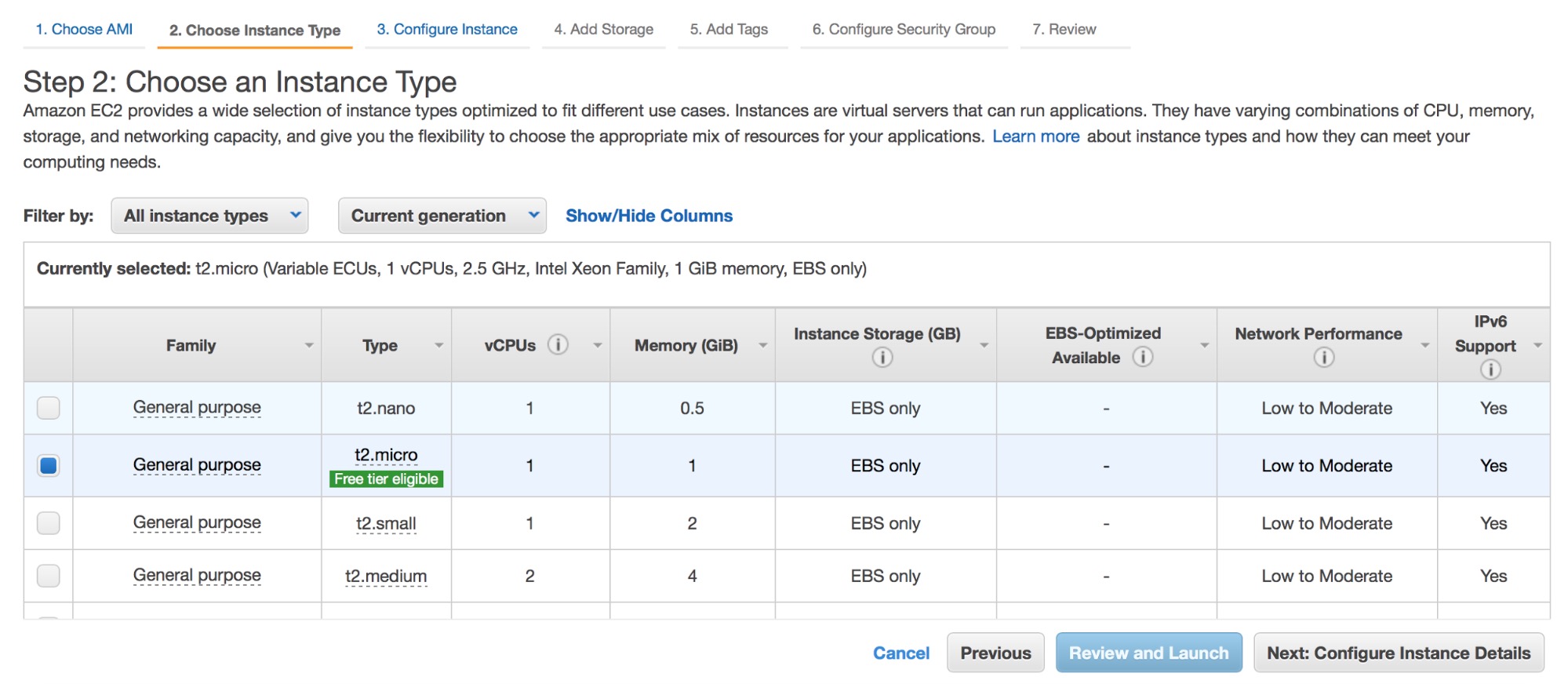
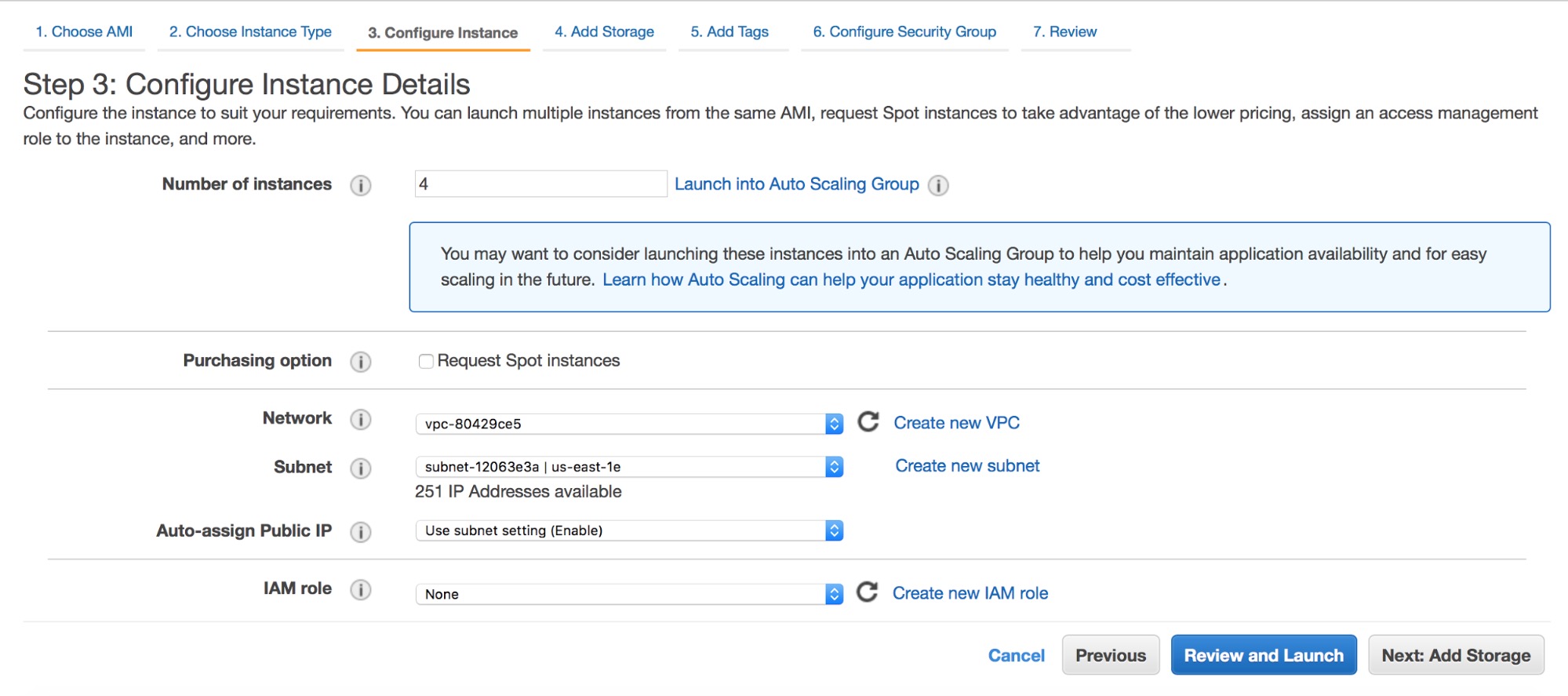
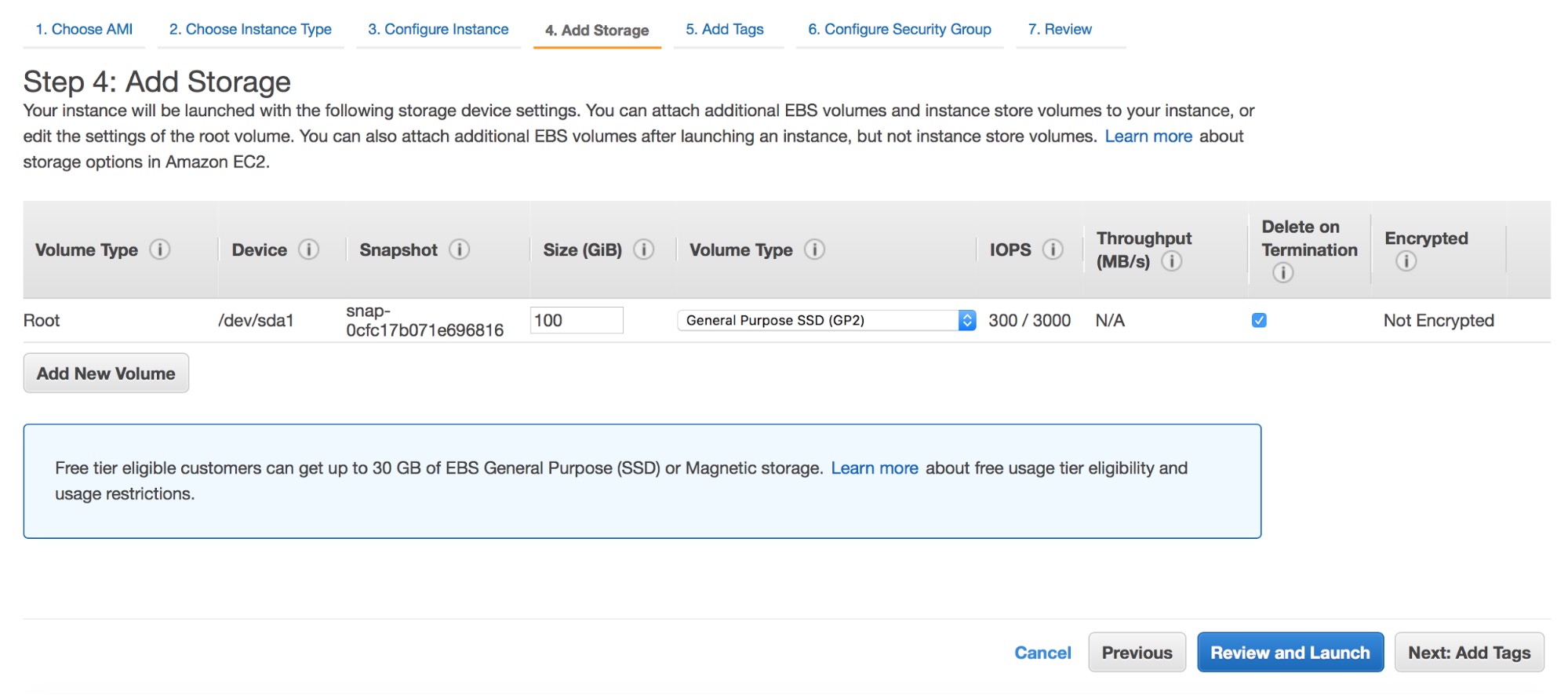
We’ve had Zabbix templates for ClusterControl available for three years now, so that Zabbix is able to connect to ClusterControl and retrieve monitoring data as well as alerts. We recently rewrote major parts of the templates to use the ClusterControl RPC interface.
In this blog post, we’ll have a look at what’s new. Note that we provide a bunch of other integrations with third party tools that you can take advantage of.
What has Changed?
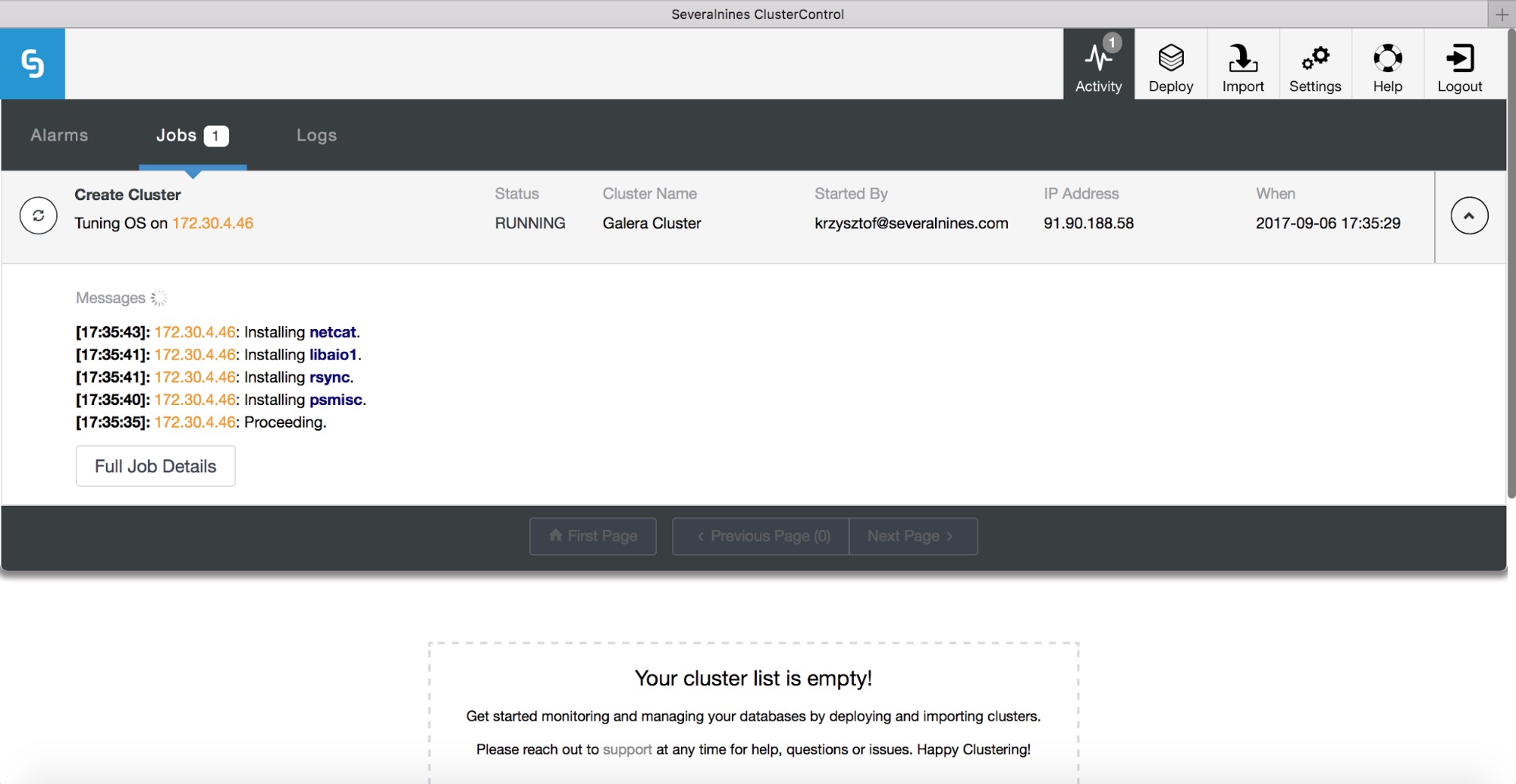
In the older version, the Zabbix plugin made use of the ClusterControl CMONAPI to retrieve monitoring data, process the output and make it understandable to the Zabbix agent. Since version 1.3, ClusterControl switched to a new interface called CMON RPC which listens on port 9500 on the ClusterControl node (9501 if you run on TLS). This new API is an improved version of the CMONAPI interface. So the agent script now communicates with ClusterControl through this RPC interface. If you are on version 1.3 and later, you should upgrade to this new script as the old one will not work anymore. Some system calls in CMONAPI have been completely removed and replaced by CMON RPC.
Another significant change is you don't need to configure the RPC URL and token directly, as the script will automatically read the configuration options directly from ClusterControl's bootstrap.php file (default to /var/www/html/clustercontrol/bootstrap.php). Due to these changes, we deprecated another 2 files inside this template, which are clustercontrol.conf (configuration file for CMONAPI URL and token) and clustercontrol_api.sh (curl wrapper to connect to CMONAPI). The same dependencies are still required, like php-curl and php-cli, as explained in the readme file of this template.
Monitoring Data
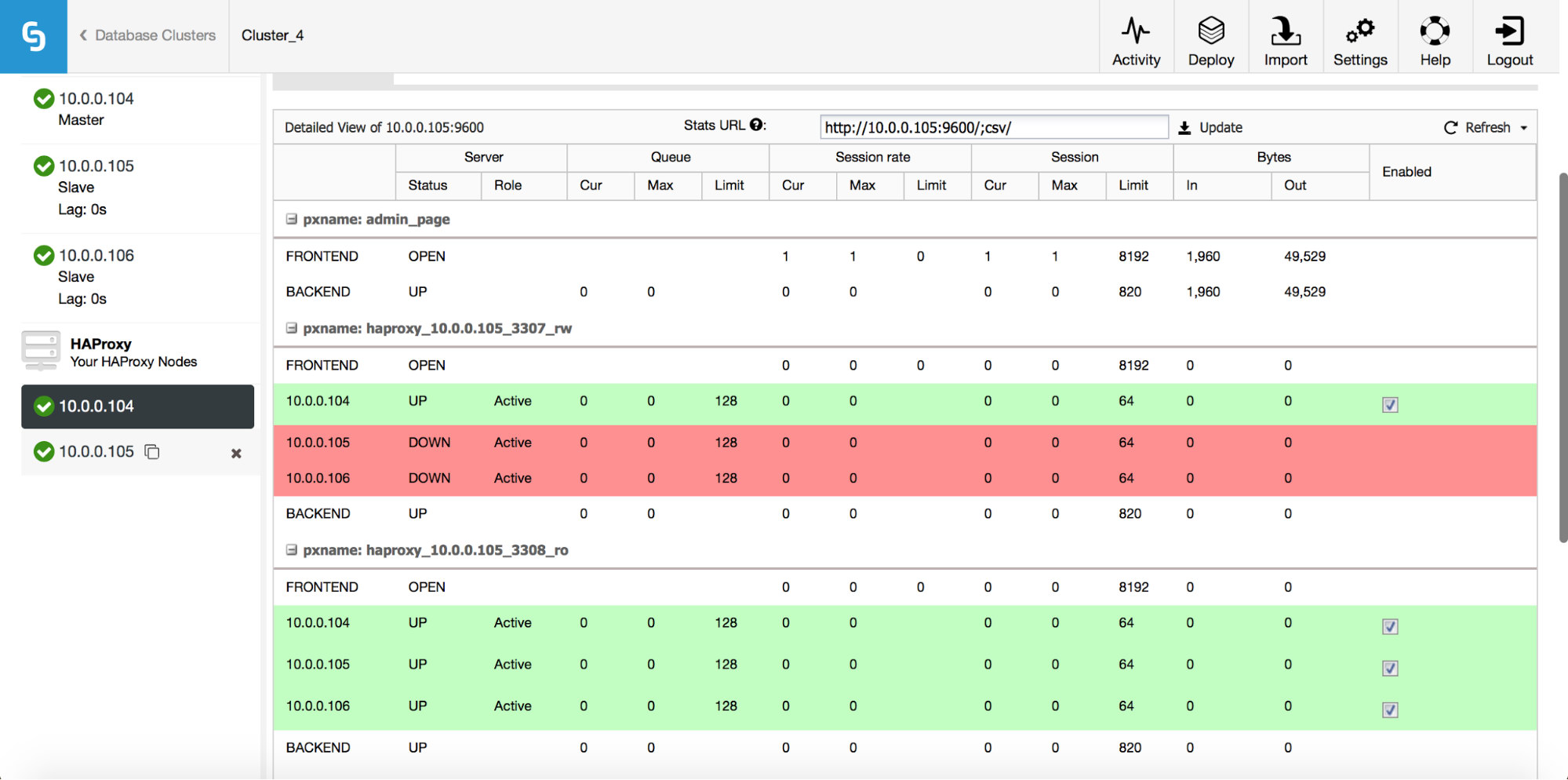
The ClusterControl template returns the following monitoring data from multiple clusters:
- Database cluster’s status - Report the cluster state - active, failed, degraded and unknown.
- ClusterControl alarms (critical/warning) - Report the number of ClusterControl alarms based on severity.
As well as ClusterControl related services:
- ClusterControl controller service (cmon)
- ClusterControl web SSH service (cmon-ssh)
- ClusterControl notification service (cmon-events)
It also supports multiple clusters, where you can specify the components and clusters to be monitored by the agent. You may skip some clusters (e.g, test cluster) for alerting by simply excluding the cluster ID from the list. The previous version had backup status as part of the monitoring data. However in this version, backup is a sub-component of alarms so monitoring the alarms should be enough.
Example Deployment
Installing the template should be pretty straightforward. Consider the following setup:

Our setup consists of a Galera Cluster, a standalone PostgreSQL server and two MySQL Replication nodes, all managed by a ClusterControl instance. The Zabbix agent will be installed on the ClusterControl node, and it uses some reporting scripts to talk to ClusterControl to retrieve monitoring data. The Zabbix server will use a ClusterControl template to talk to the Zabbix agent.
Zabbix Agent
Installation instructions can be found on our GitHub repository page. To get the template, just clone the s9s-admin repository:
$ git clone https://github.com/severalnines/s9s-adminCreate a template directory for ClusterControl under /var/lib/zabbix and copy the scripts directory into it:
$ mkdir -p /var/lib/zabbix/clustercontrol $ cp -Rf ~/s9s-admin/plugins/zabbix/agent/scripts /var/lib/zabbix/clustercontrolCopy the ClusterControl template user parameter file into /etc/zabbix/zabbix.agent.d/:
$ cp -f ~/s9s-admin/plugins/zabbix/agent/userparameter_clustercontrol.conf /etc/zabbix/zabbix.agent.d/This template uses the ClusterControl CMON RPC interface to collect stats. The script will copy /var/www/html/clustercontrol/bootstrap.php into the template directory to read ClusterControl configuration options. If you are running on a non-default path for the ClusterControl UI, configure the exact path manually inside clustercontrol_stats.php, similar to the example below:
$BOOTSTRAP_PATH = '/var/www/html/clustercontrol/bootstrap.php';Test the script by invoking a cluster ID and test argument:
$ /var/lib/zabbix/clustercontrol/scripts/clustercontrol_stats.sh 1,2,3,4,5 test Cluster ID: 1, Cluster Name: MariaDB 10.1, Cluster Type: galera, Cluster Status: STARTED Cluster ID: 2, Cluster Name: PostgreSQL, Cluster Type: postgresql_single, Cluster Status: STARTED Cluster ID: 3, Cluster Name: MySQLRep, Cluster Type: replication, Cluster Status: STARTED Cluster ID 4 not found. Cluster ID 5 not found.** This example shows that the ClusterControl instance has 3 clusters, although we defined 5 cluster IDs in the command line.
You should get an output of your database cluster summary, indicating the script is able to retrieve information using the provided ClusterControl RPC interface with the correct token in bootstrap.php.
Finally, restart the Zabbix agent:
$ service zabbix-agent restart
Installation of the Zabbix agent is now complete.
Zabbix Server
Download the Zabbix template file from here to your desktop.
Import the XML template using the Zabbix UI (Configuration -> Templates -> Import). Verify if the import is OK by going to Configuration -> Templates -> ClusterControl Template -> Items and you should see something like this:
![]()
Create/edit hosts and link them to the template "ClusterControl Template" (Configuration -> Hosts -> choose a host -> Templates tab):

You are done. The following is what you can expect to see in your Zabbix frontend UI if something goes wrong:

Summary
ClusterControl has a sophisticated alarming system. In cases where Zabbix is the main monitoring and alerting tool, this simple integration will unify your database alerts into Zabbix.
We would be happy to continue and improve this template, do let us know what kind of information that you would like to see in Zabbix in the comments section below.