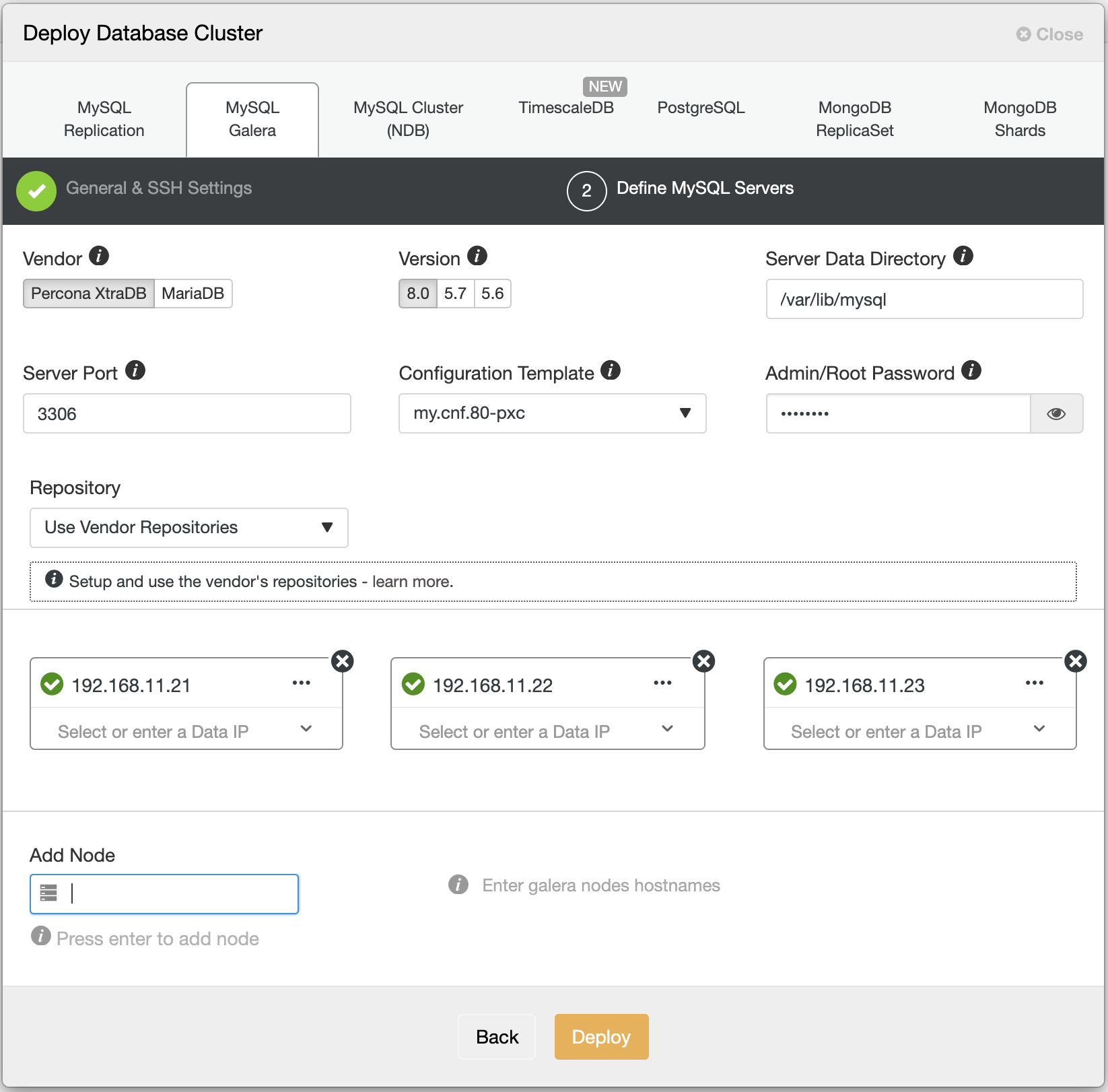
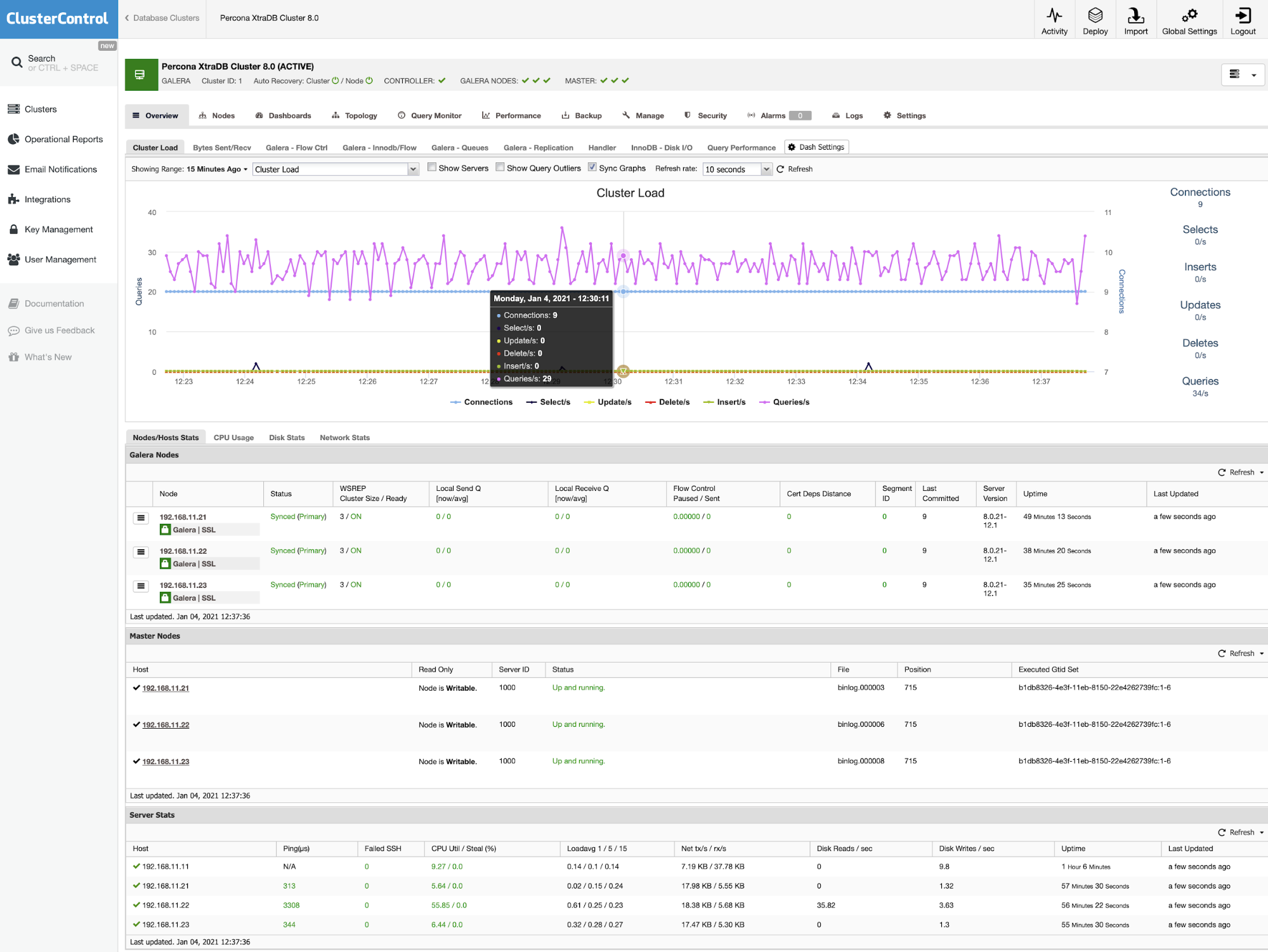
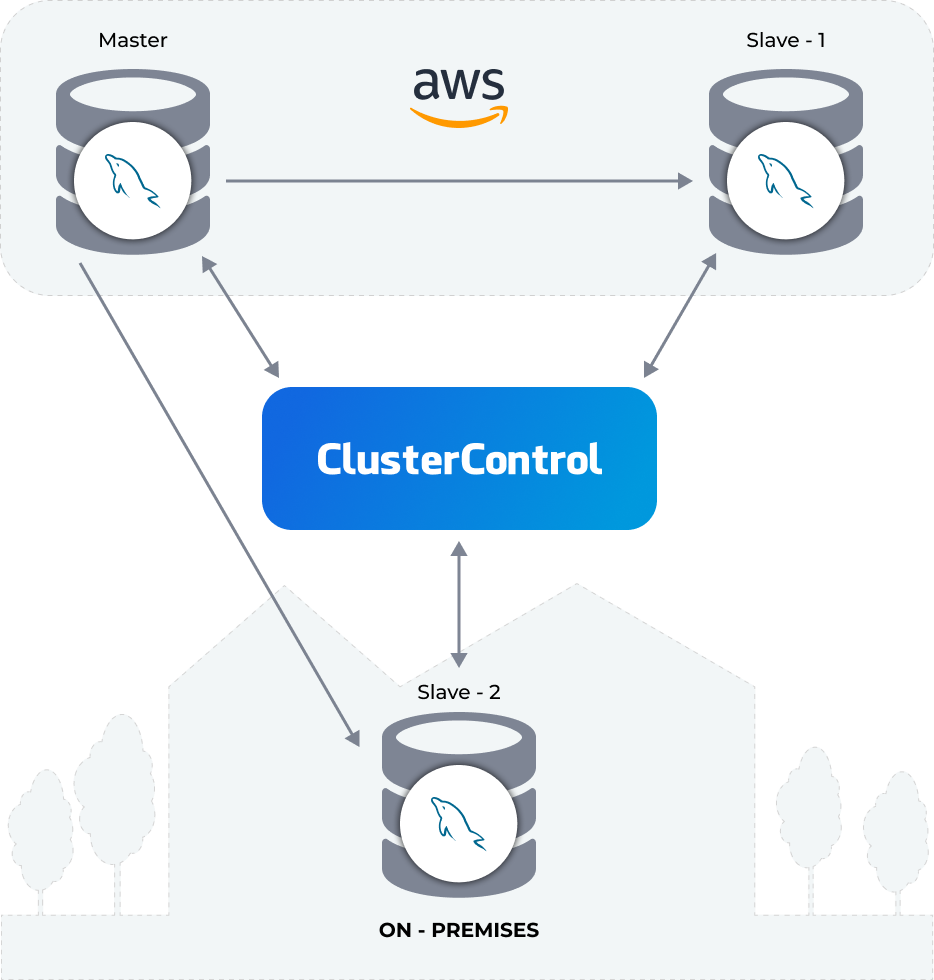
No matter what kind of application/system you are running, you will always need to manage and monitor your databases. Even in a small project, you want to be sure everything is going fine or if you might need to change something, and there are also different tasks to perform if you want to ensure that your systems will run in a healthy way.
This COVID-19 pandemic increased the working and studying from home in an exponential way, so many platforms took an important role in this situation, and probably one of the most important was Moodle.
Moodle is a learning platform designed to provide educators, administrators, and learners with a single robust, secure, and integrated system to create personalized learning environments. It supports different database technologies (e.g. MariaDB, MySQL, PostgreSQL, etc).
In this blog, we will take a look at what you need to manage and monitor in a Moodle Database, and how you can do it easier using ClusterControl.
Moodle Database Configuration
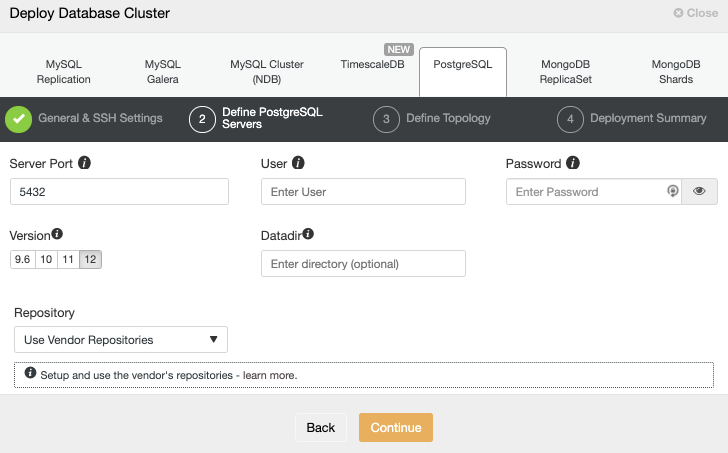
First, let’s take a look at the Moodle Database configuration file: /var/www/html/moodle/config.php:
//=========================================================================
// 1. DATABASE SETUP
//=========================================================================
$CFG->dbtype = 'mariadb'; // 'pgsql', 'mariadb', 'mysqli', 'sqlsrv' or 'oci'
$CFG->dblibrary = 'native'; // 'native' only at the moment
$CFG->dbhost = '10.10.10.134'; // eg 'localhost' or 'db.isp.com' or IP
$CFG->dbname = 'moodle'; // database name, eg moodle
$CFG->dbuser = 'moodleuser'; // your database username
$CFG->dbpass = 'moodlepass'; // your database password
$CFG->prefix = 'mdl_'; // prefix to use for all table names
$CFG->dboptions = array(
'dbpersist' => false,
'dbsocket' => false,
'dbport' => '',
'dbhandlesoptions' => false,
'dbcollation' => 'utf8mb4_unicode_ci',
);This is the basic database configuration, but there is also an optional configuration commented out in the same file:
'connecttimeout' => null,
'readonly' => [
'instance' => [
[
'dbhost' => '10.10.10.135',
'dbport' => '',
'dbuser' => '',
'dbpass' => '',
],
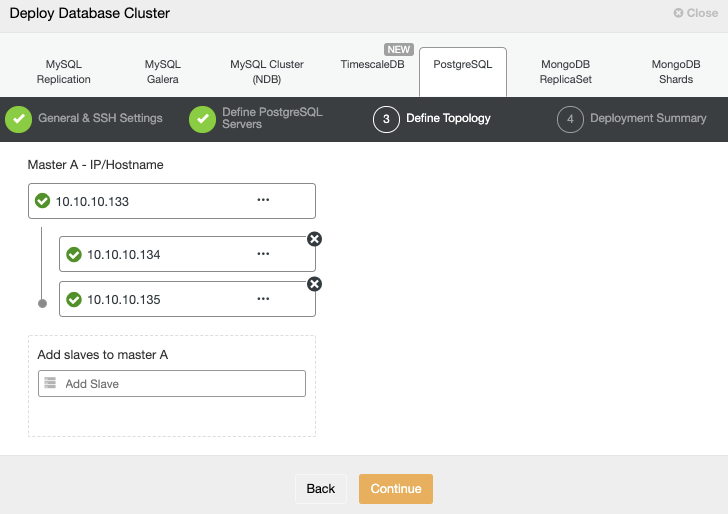
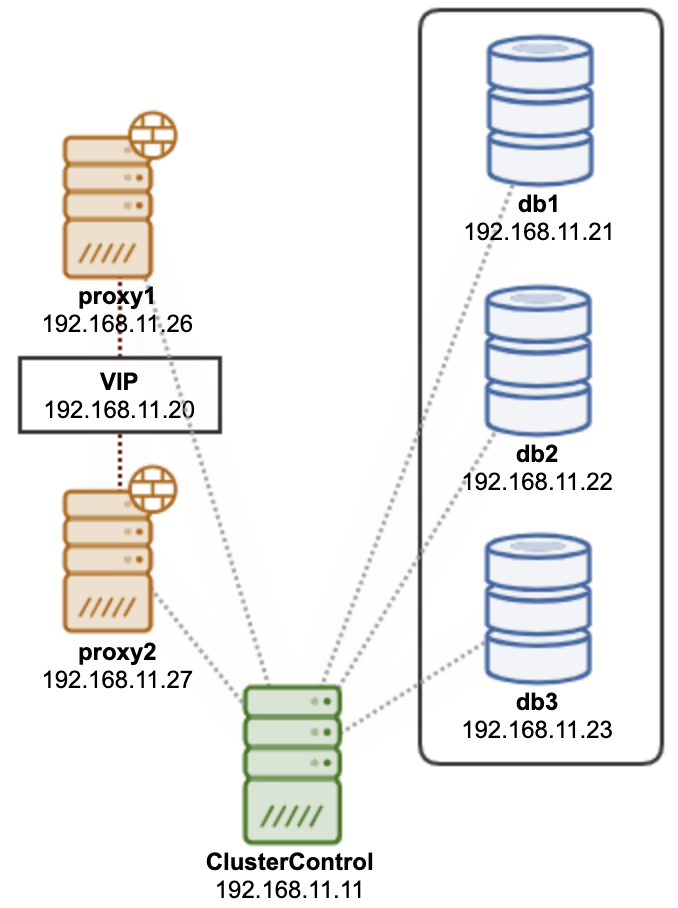
…So, it means you can configure slave read-only nodes to balance the read traffic and increase the performance. Another option is to use a Load Balancer, who will send the traffic to the available nodes and it could be able to help on failover tasks.
Now let’s see what you should monitor in this Moodle Database.
What to Monitor in the Moodle Database
When monitoring systems, there are two main things to take into account: the operating system and the database itself. You will need to define which metrics you are going to monitor from both sides and how you are going to do it. You need to monitor the metric always in the context of your system, and you should look for alterations on the behavior pattern.
Keep in mind that when one of your metrics is affected, it can also affect others, making troubleshooting of the issue more complex. Having a good monitoring and alerting system is important to make this task as simple as possible.
Operating System Monitoring
One important thing (which is common to all database engines and even to all systems) is to monitor the Operating System behavior. Here are some points to check.
CPU Usage
An excessive percentage of CPU usage could be a problem if it is not usual behavior. In this case, it is important to identify the process/processes that are generating this issue. If the problem is the database process, you will need to check what is happening inside the database.
RAM Memory or SWAP Usage
If you are seeing a high value for this metric and nothing has changed in your system, you probably need to check your database configuration. Depending on the database technology, there are different parameters to specify the amount of memory to be used for different database tasks.
Disk Usage
An abnormal increase in the use of disk space or an excessive disk access consumption are important things to monitor as you could have a high number of errors logged in the log file or a configuration that could generate an important disk access consumption instead of using memory to process the queries.
Load Average
It is related to the three points mentioned above. A high load average could be generated by an excessive CPU, RAM, or Disk Usage.
Network
A network issue can affect all the systems as the application can’t connect (or connect losing packages) to the database, so this is an important metric to monitor indeed. You can monitor latency or packet loss, and the main issue could be a network saturation, a hardware issue, or just a bad network configuration.
Database Monitoring
Monitoring your database is not only important to see if you are having an issue, but also to know if you need to change something to improve your database performance, that is probably one of the most important things to monitor in a database. Let’s see some metrics that are important for this.
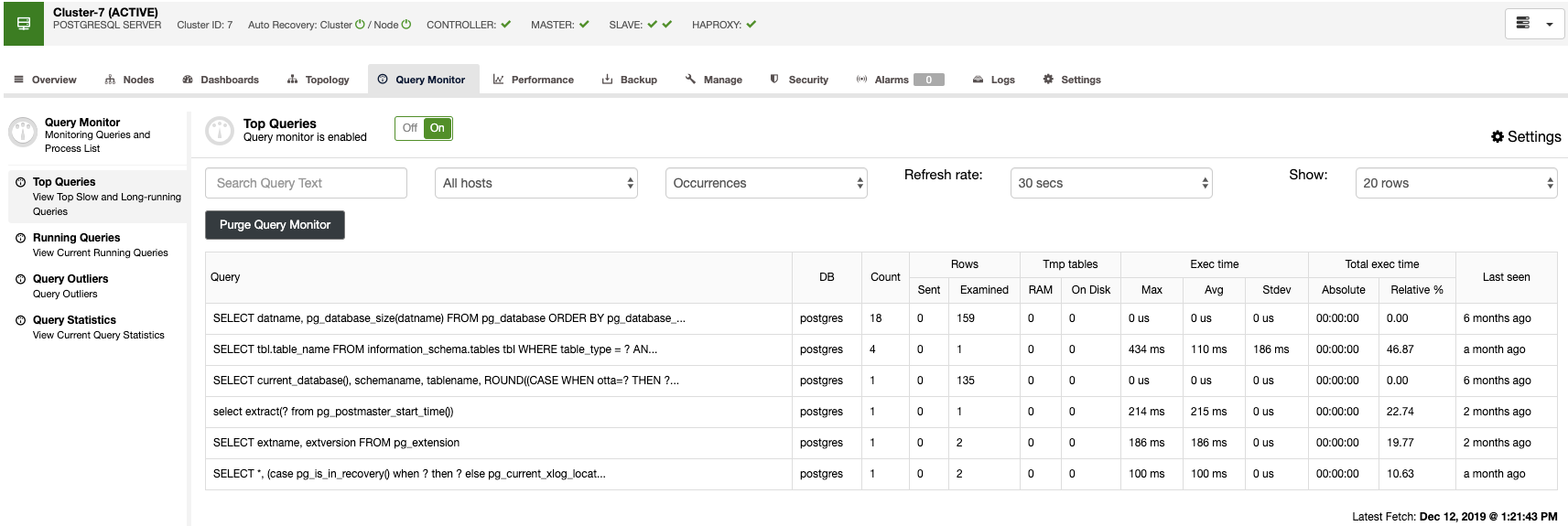
Query Monitoring
In general, the databases are configured with compatibility and stability in mind by default, so you need to know your queries and his pattern, and configure your databases depending on the traffic that you have. Here, you can use the EXPLAIN command to check the query plan for a specific query, and you can also monitor the amount of SELECT, INSERT, UPDATE or DELETEs on each node. If you have a long query or a high number of queries running at the same time, that could be a problem for all the systems.
Active Sessions
You should also monitor the number of active sessions. If you are near the limit, you need to check if something is wrong or if you just need to increment the max connection value in the database configuration. The difference in the number can be an increase or decrease of connections. Bad usage of connection pooling, locking, or network issues are the most common problems related to the number of connections.
Database Locks
If you have a query waiting for another query, you need to check if that other query is a normal process or something new. In some cases, if somebody is making an update on a big table, for example, this action can be affecting the normal behavior of your database, generating a high number of locks.
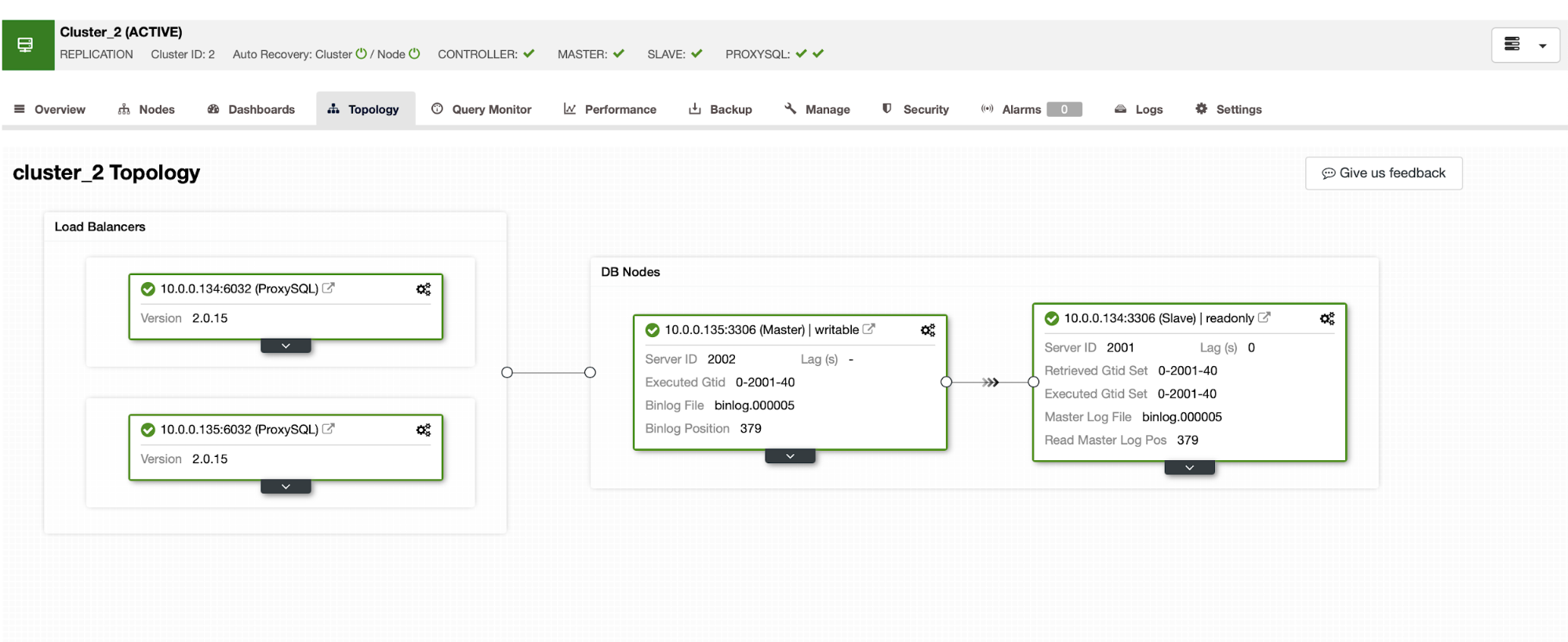
Replication
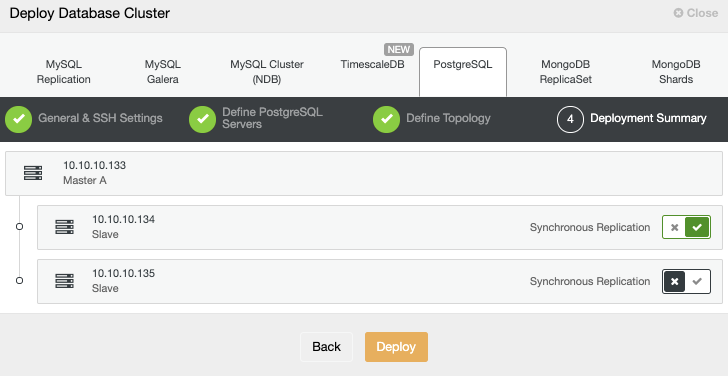
The key metrics to monitor for replication are the lag and the replication state. The most common issues are networking issues, hardware resource issues, or under dimensioning issues. If you are facing a replication issue you will need to know this asap as you will need to fix it to ensure the high availability environment.
Backups
Avoiding data loss is one of the basic DBA tasks, so you don’t only need to take the backup, you should know if the backup was completed, and if it is usable. Usually, this last point is not taken into account, but it is probably the most important check in a backup process.
Database Logs
You should monitor your database log for errors, authentication issues, or even long-running queries. Most of the errors are written in the log file with detailed useful information to fix it.
Notifications & Alerting
Just monitoring a system is not enough if you don’t receive a notification about each issue. Without an alerting system, you should go to the monitoring tool to see if everything is fine, and it could be possible that you are having a big issue since many hours ago. This alerting job could be done by using email alerts, text alerts, or other tools like slack.
Moodle Database Management Tasks
Monitoring a database doesn’t make sense if you can’t manage it. If you detect an issue, you will need to fix it, or even if everything looks fine, you should be able to perform some basic management tasks that we will mention below.
Failover
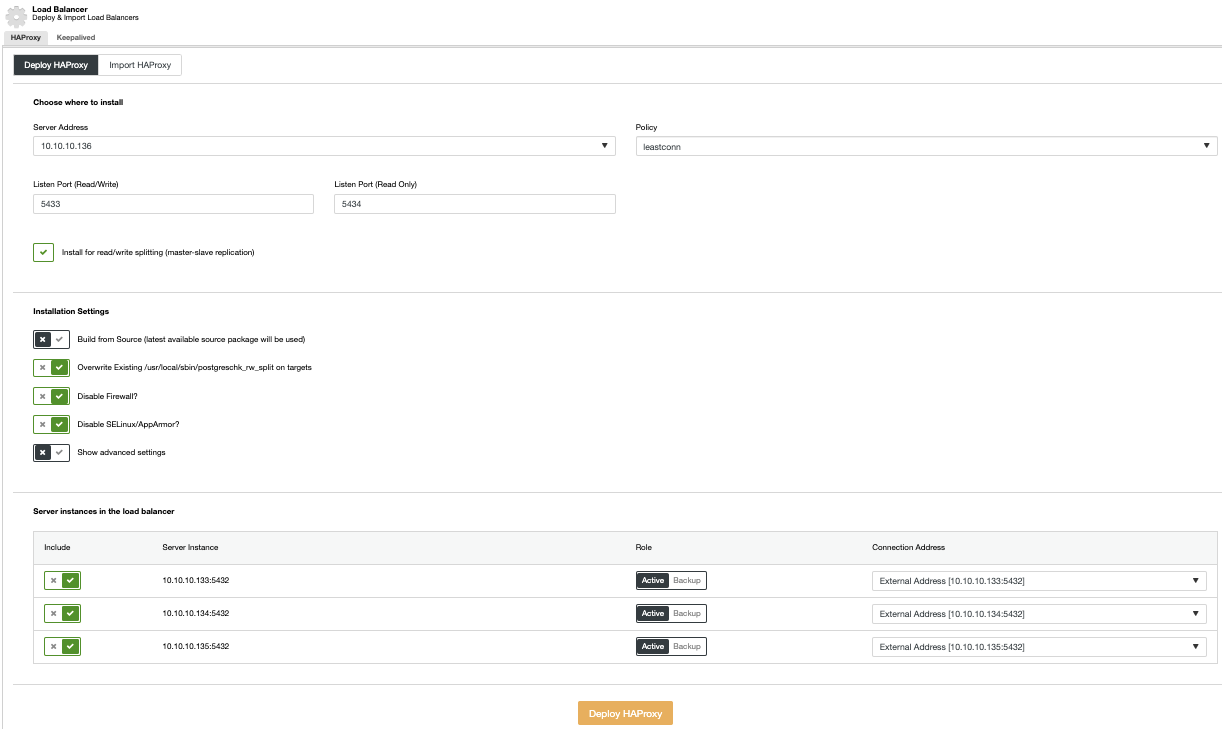
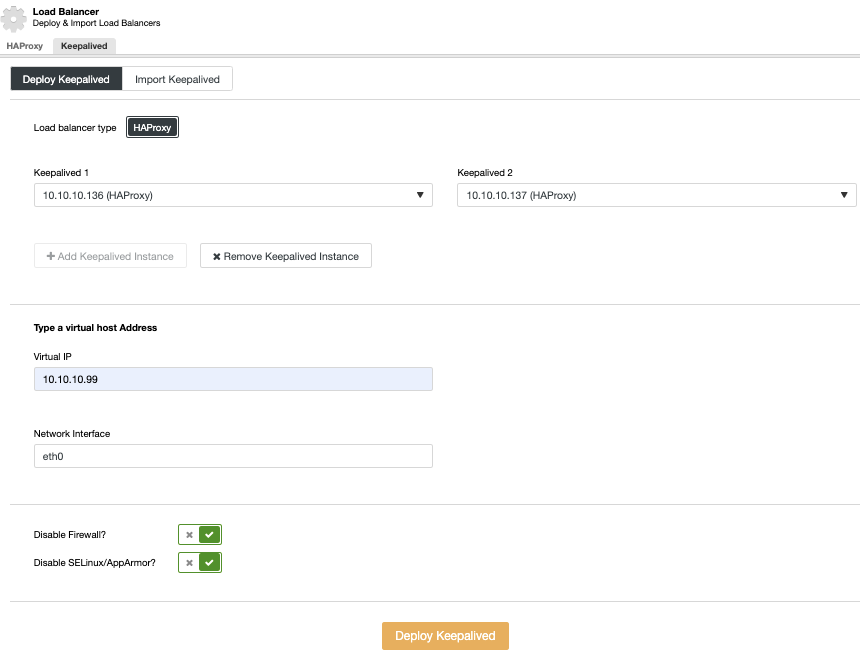
This is an important task in a High Availability environment. It could be manual or automatic, but it is a must to be able to keep your database running in a DRP (Disaster Recovery Plan) or even in a maintenance planned task. You can also add a Load Balancer here, to avoid any change in your application after performing a failover task.
Scaling
Another important task is to scale-out your database topology, which means adding more database nodes. You can do it if you are expecting or having more traffic for any reason.
Backup Scheduling
Backups are a very important part of any DRP, to prevent data loss in the event of an accident or hardware failure. It might not always be enough to guarantee an acceptable Recovery Point Objective (RPO) but is a good first approach. Also, you should define a Recovery Time Objective (RTO) according to your company requirements. There are many ways to reach the RTO value, it depends on the company goals, and in any case, scheduling backups in a correct way is the key.
Backup verification plays also a very important role here. Rest assured, your backup must be a valid type of backup and is a reliable copy when a crisis takes place. Adding the mechanism to store your backup not only in your premises or datacenter but also store it elsewhere securely like in the cloud or to AWS S3 or Google Cloud Storage for example.
Database Security
Security is usually the major primary concern when it comes to managing your database cluster. Enable or disable remote access, who will be able to access it, how to add security restrictions, or how to manage the users and review the user's permission are pretty common topics in this section.
Centralized Database Logs
Logs Centralization provides you a very convenient way to investigate and implement a security analysis tool to understand your database clusters and how they behave. In case you need to investigate a cluster-wide problem and see what has been going through your database clusters, proxies, or load balancers. It is very convenient to just look at one place.
It's really difficult to find a tool to monitor all the necessary metrics for your Moodle Database and, at the same time, allow you to manage your database cluster. In general, you will need to use more than one tool and even some scripting will need to be made. One way to centralize the managing and monitoring tasks is by using ClusterControl, which provides you with features like backup management, monitoring and alerting, deployment and scaling, automatic recovery, and more important features to help you manage your databases. All these features on the same system.
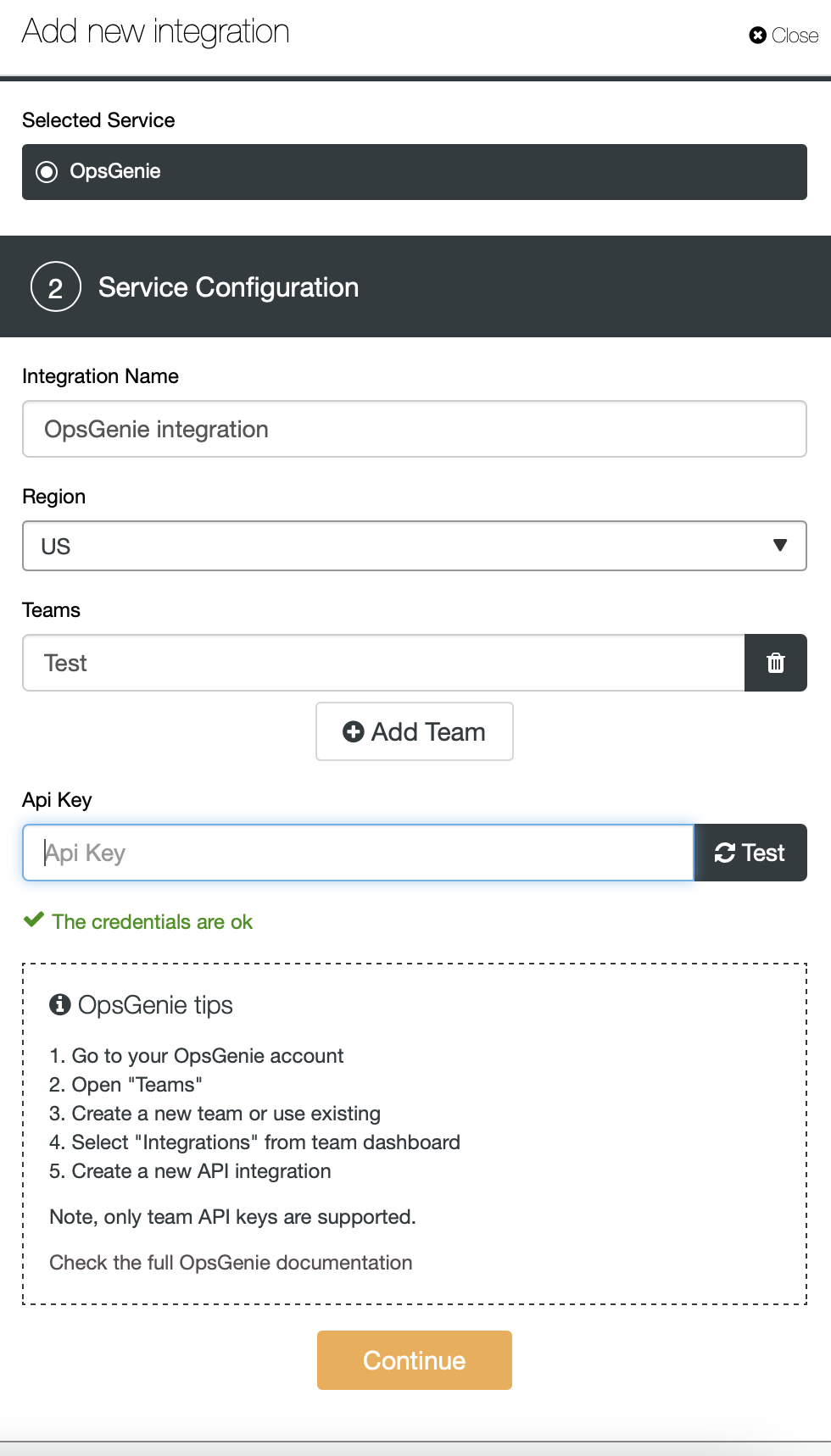
Managing and Monitoring Your Moodle Database with ClusterControl
As we mentioned, using ClusterControl you can perform different management and monitoring tasks like add/remove load balancers, add/remove slave nodes, automatic failover and recovery, backups, create/modify advisors, create/modify dashboards, and more. Let’s see some of these features.
ClusterControl Monitoring
ClusterControl allows you to monitor your database servers in real-time. It has a predefined set of dashboards for you, to analyze some of the most common metrics mentioned above and even more.
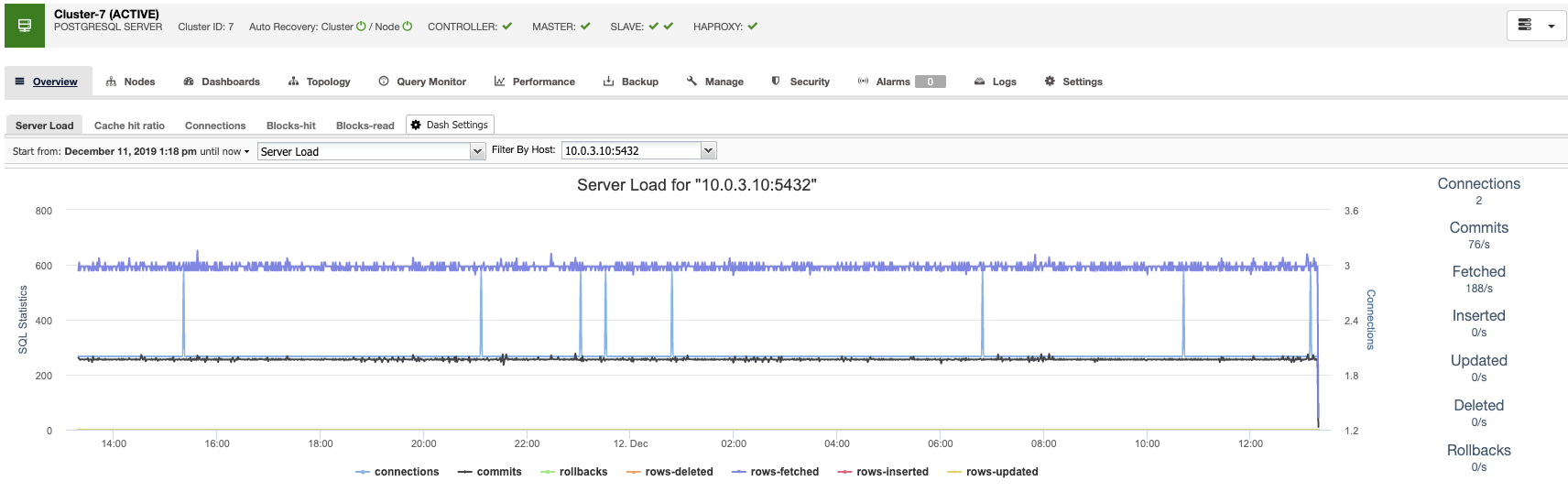
It also allows you to customize the graphs availables in the cluster, and you can enable agent-based monitoring to generate more detailed dashboards.
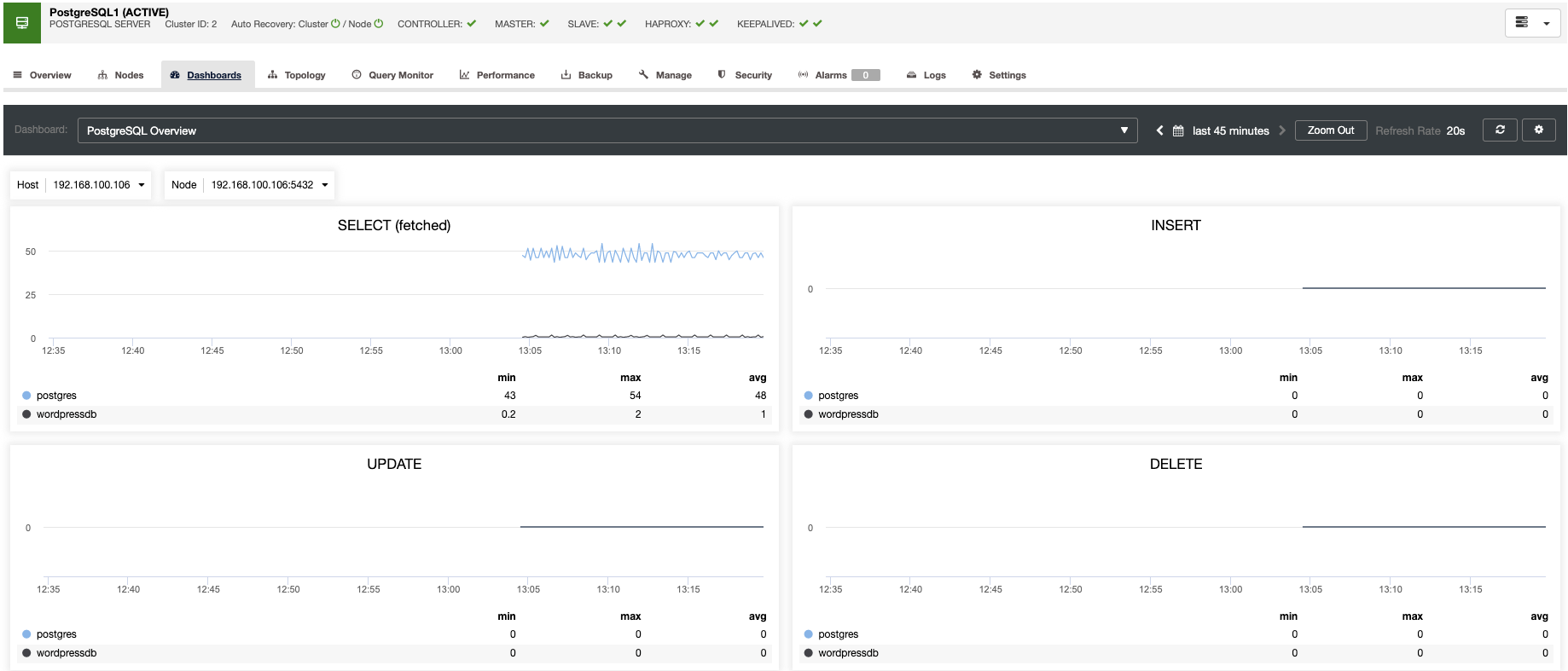
Also, you have the query monitor and the performance sections, where you can find all your database information. With these features, you can see how your database is going.
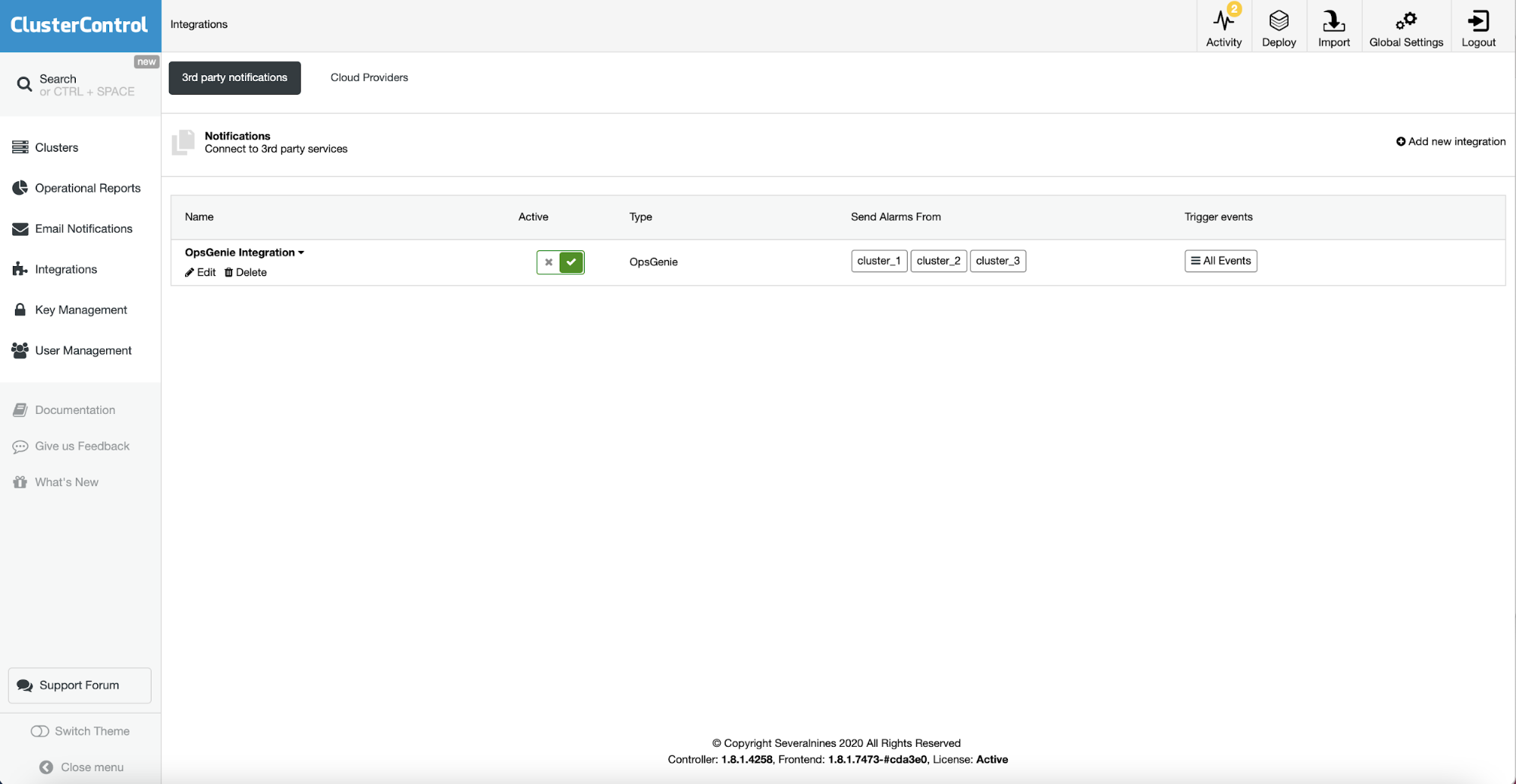
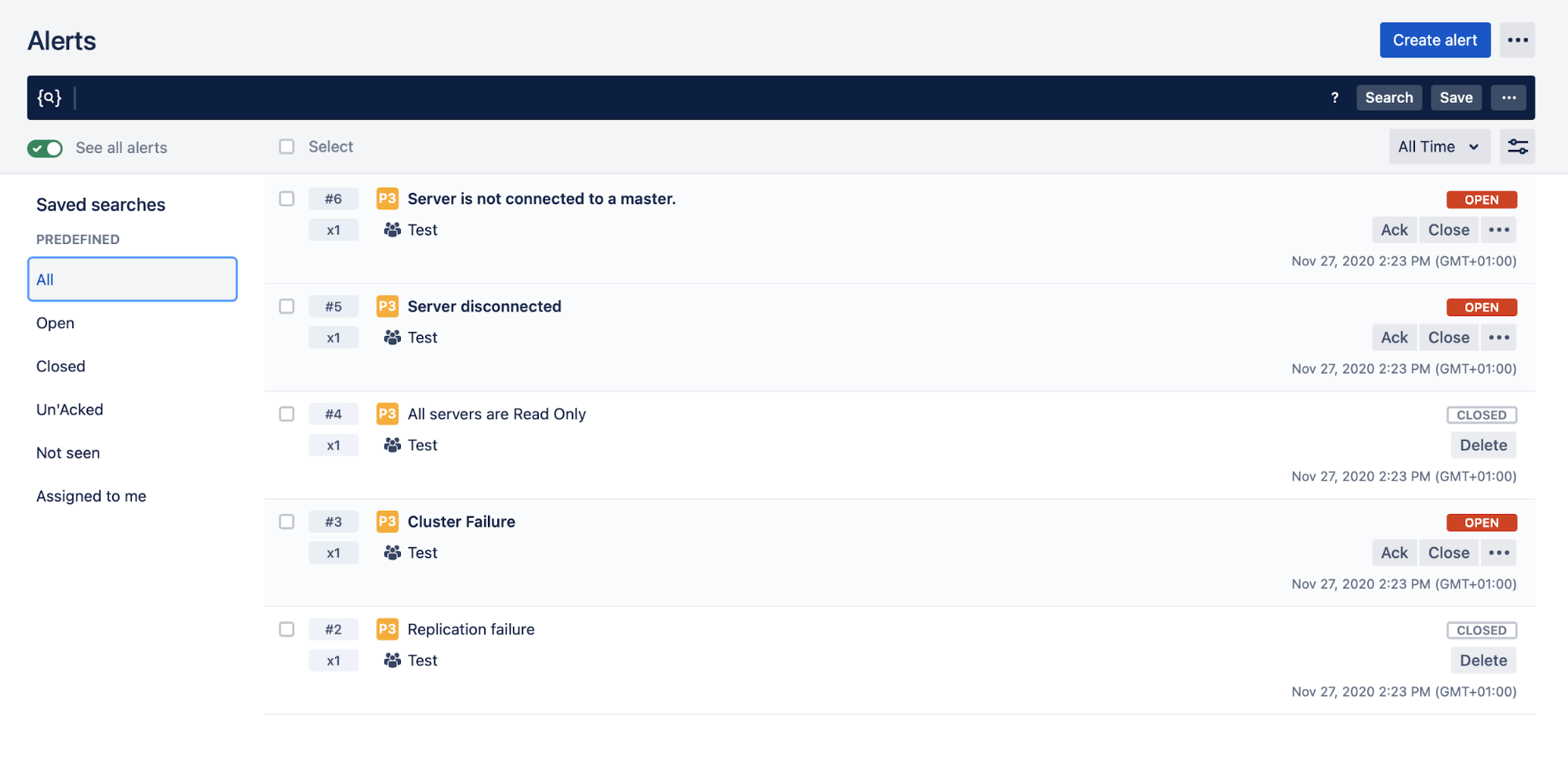
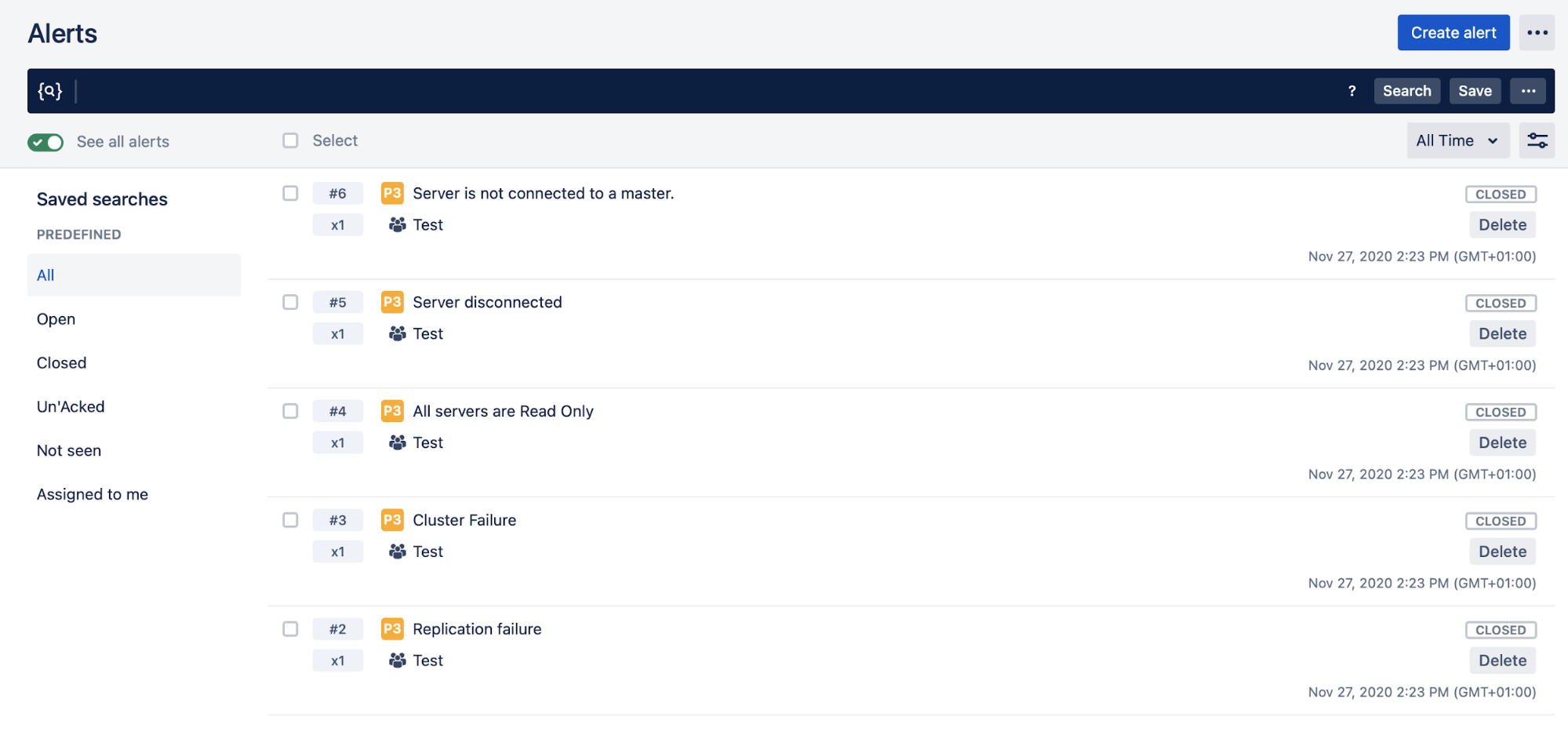
ClusterControl Alerting
You can create alerts, which inform you of events in your cluster, or integrate it with different services such as PagerDuty or Slack.
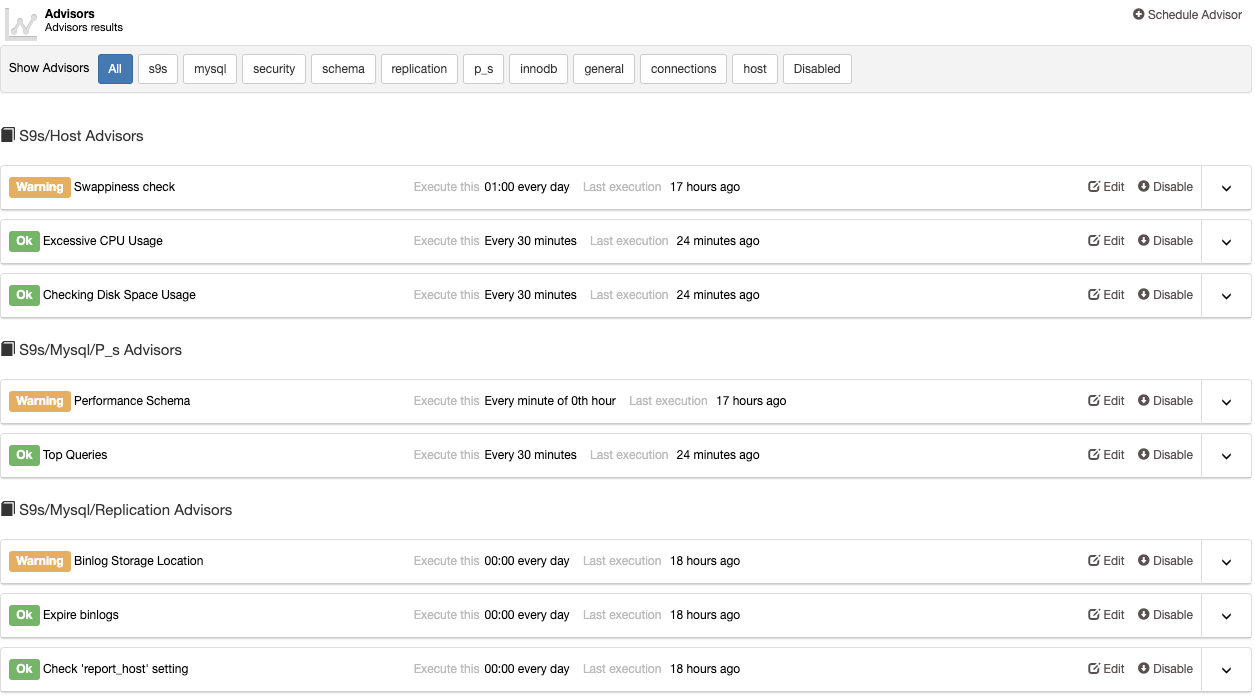
ClusterControl Scaling
To scale-out your database you can (depending on the technology that you are using) add nodes or replication slaves. Go to the Cluster Actions section to see the available actions for your topology.
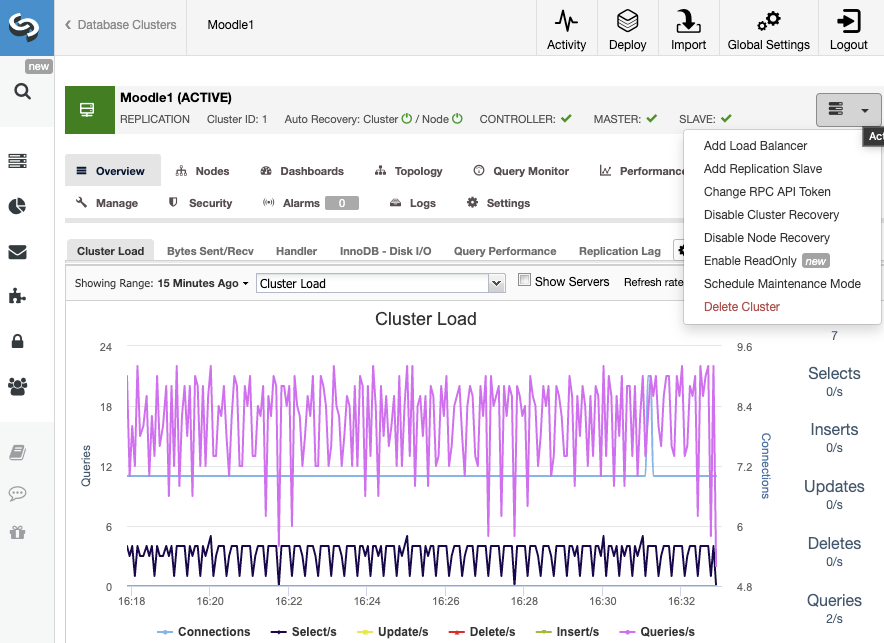
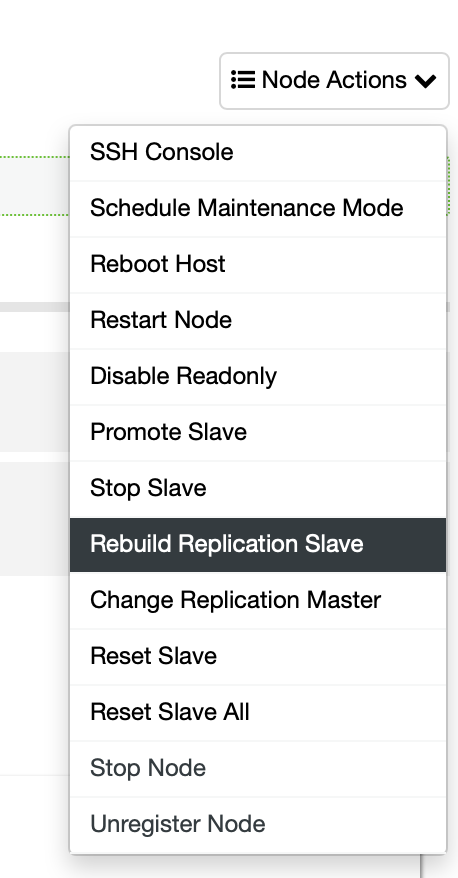
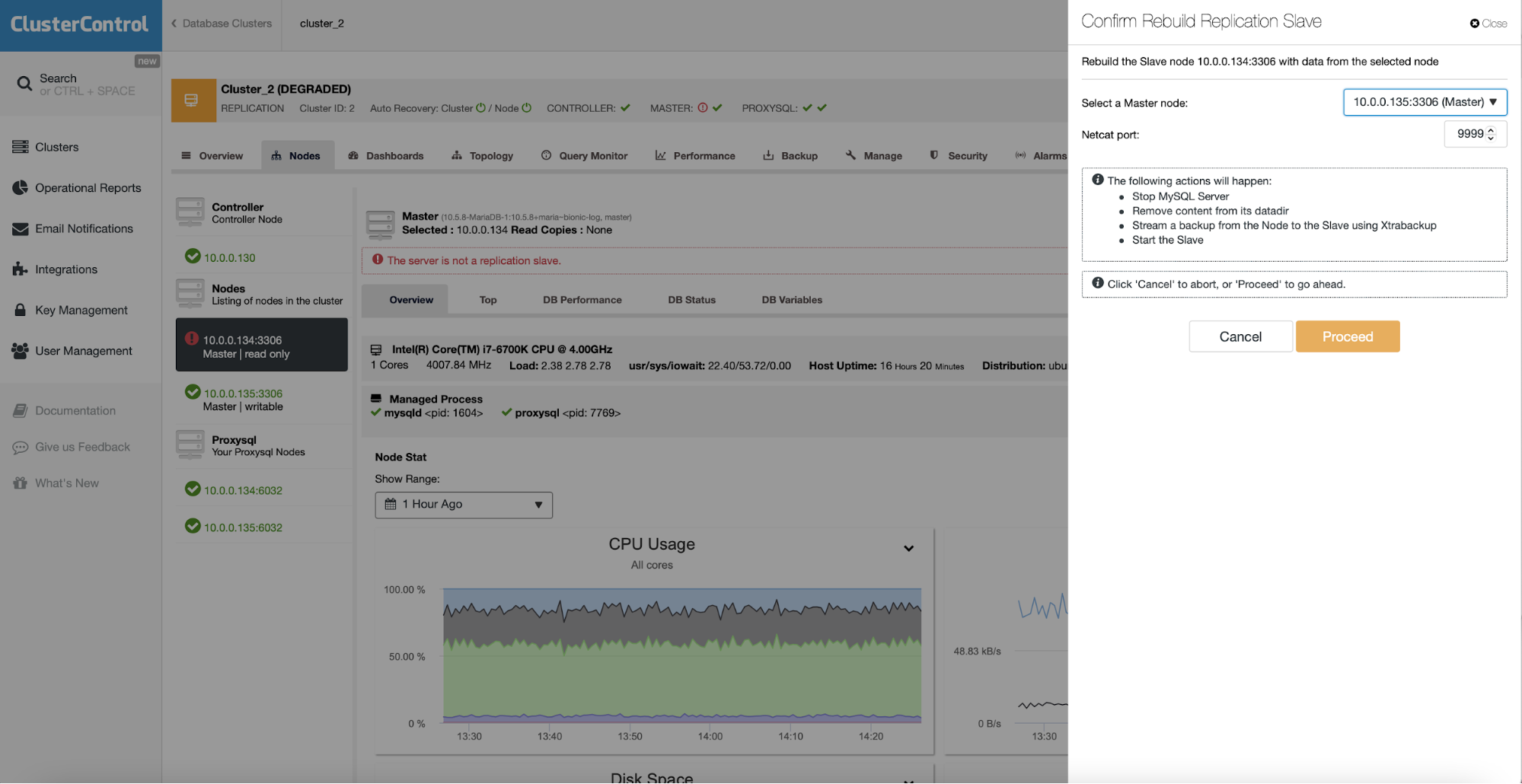
For a specific database node, you can also Reboot Host, Rebuild Replication Slave, Promote Slave, and perform more node actions with just one click.
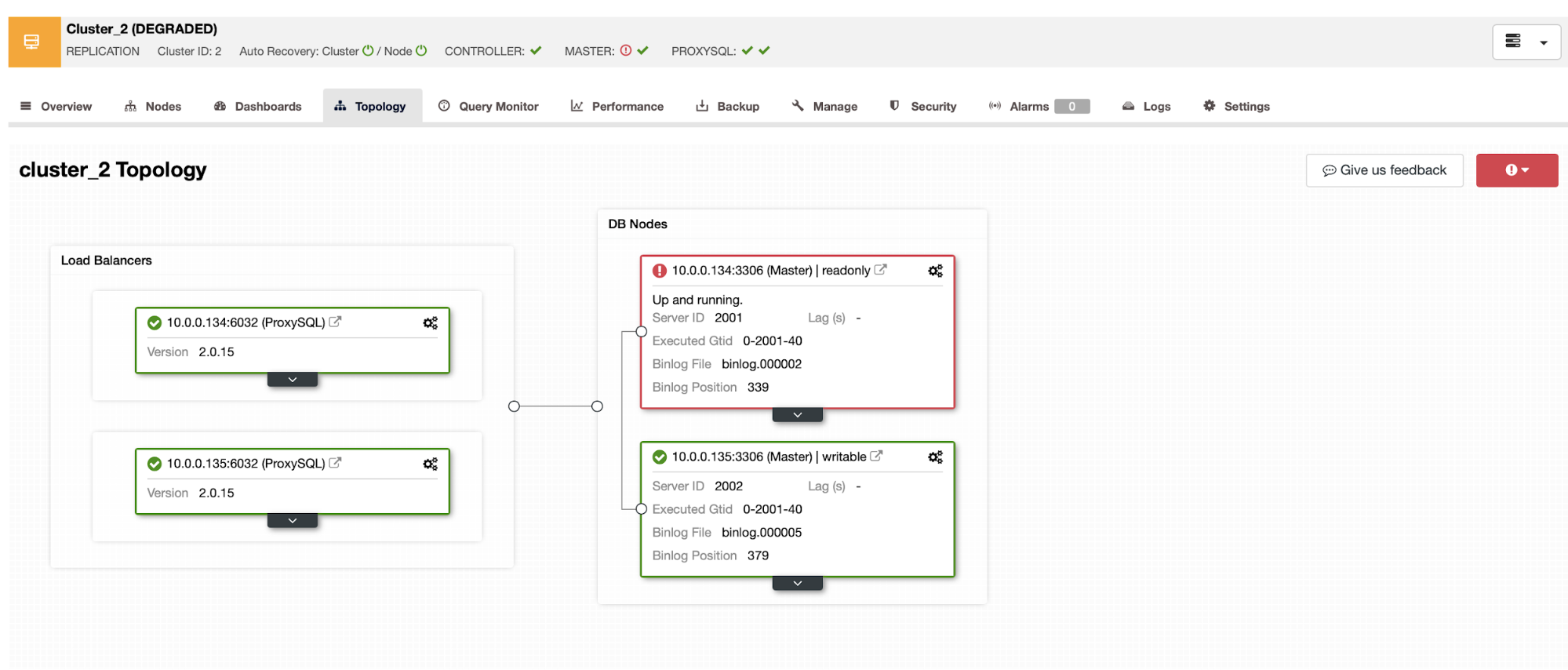
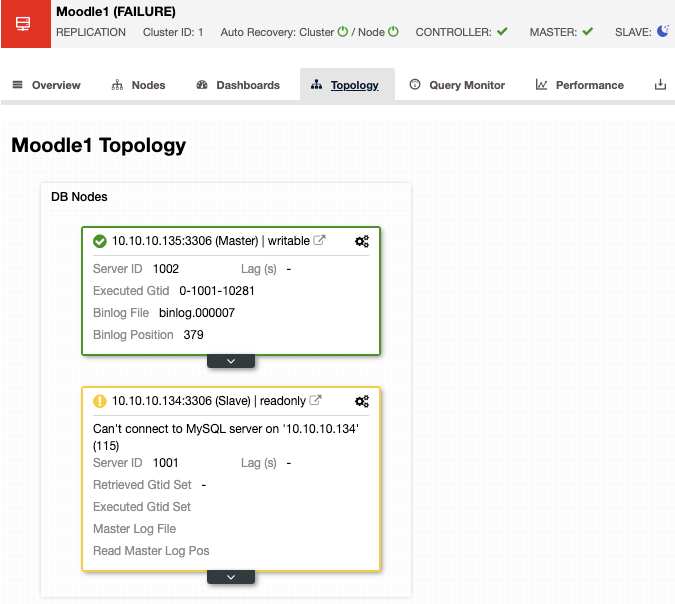
ClusterControl Failover
Having the auto-recovery feature enabled, in case of failure, ClusterControl will promote the most advanced slave and, if there is a load balancer deployed, it will change the configuration to enable the new master and disable the old one. In this way, you will have automatic failover in case of failure.
ClusterControl Backup Management
For backup management, ClusterControl centralizes it to protect, secure, and recover your data, and with the verification backup feature, you can confirm if the backup is good to go.
You can perform manual or scheduled backups using different tools like XtraBackup, Mariabackup, pg_basebackup, etc. The tool depends on the technology and you can specify this during the backup configuration process.
In ClusterControl, select your cluster and go to the "Backup" section to see your current backups. You also have PITR, Incremental/Differential Backups, Verify Backup, Restore, Create a Cluster from Backup, and more Backup Features.
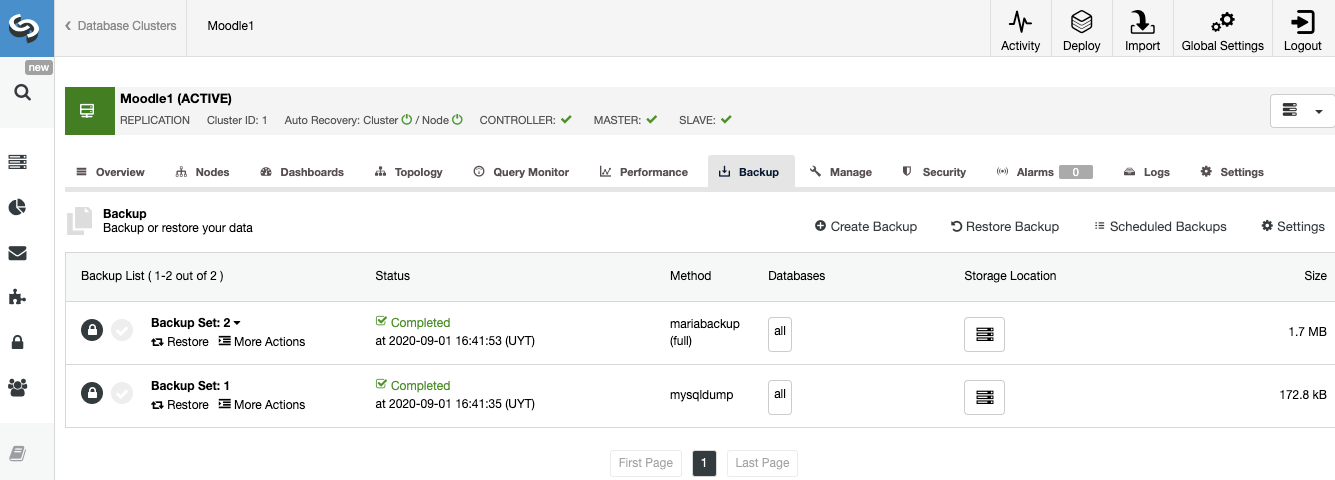
ClusterControl Security
About security, you can manage users/roles for your database cluster. Go to ClusterControl -> Select Cluster -> Manage -> Schema and Users (or User Management if you are using PostgreSQL).
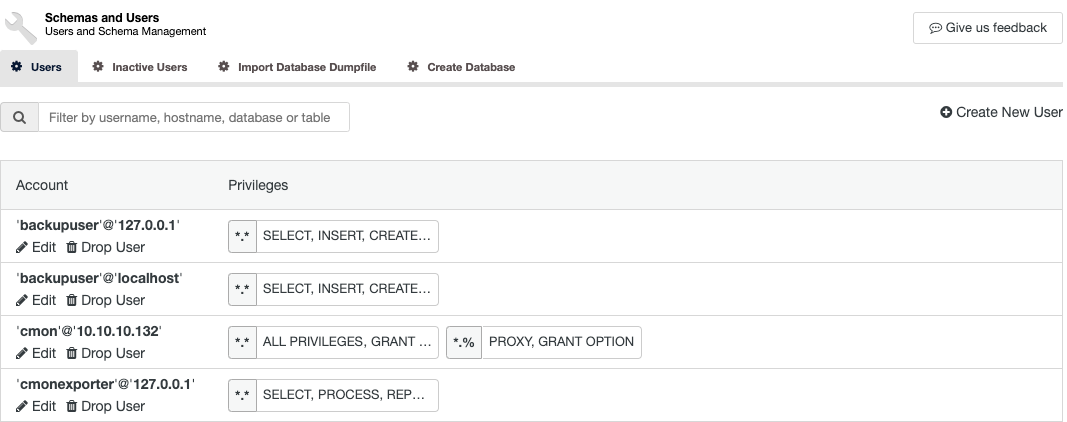
Here you can see all the accounts with the privileges assigned, and you can create a new one, or modify/edit an existing account.
In the security section, you can enable different security features like SSL or Audit Log.
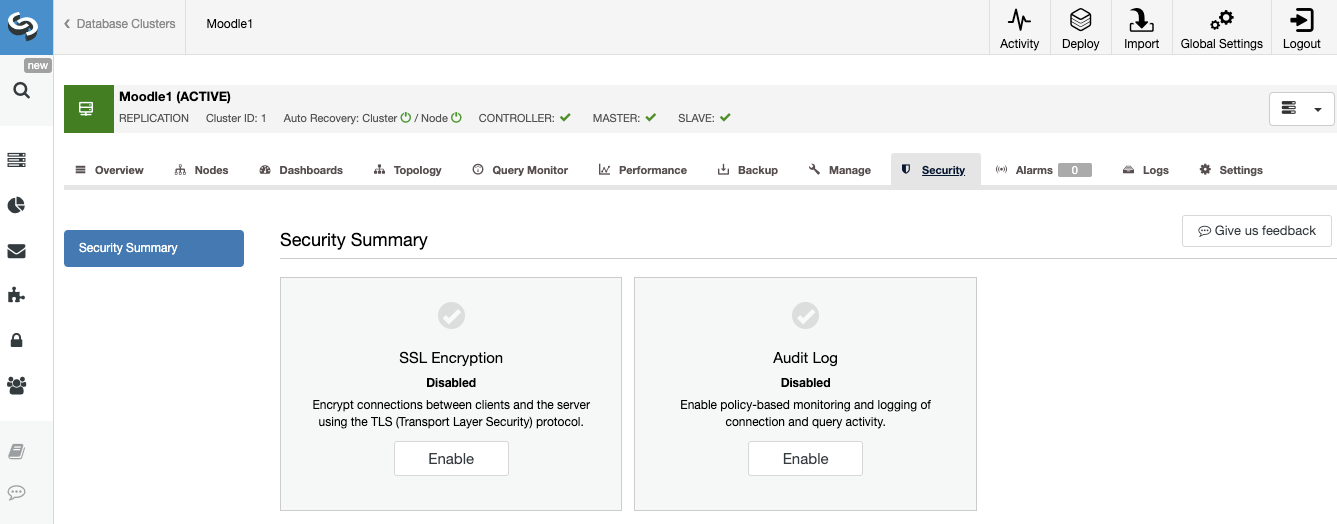
ClusterControl Centralized Logs
You don’t need to access your database node to check the logs, you can find all your database logs centralized in the ClusterControl Log section.
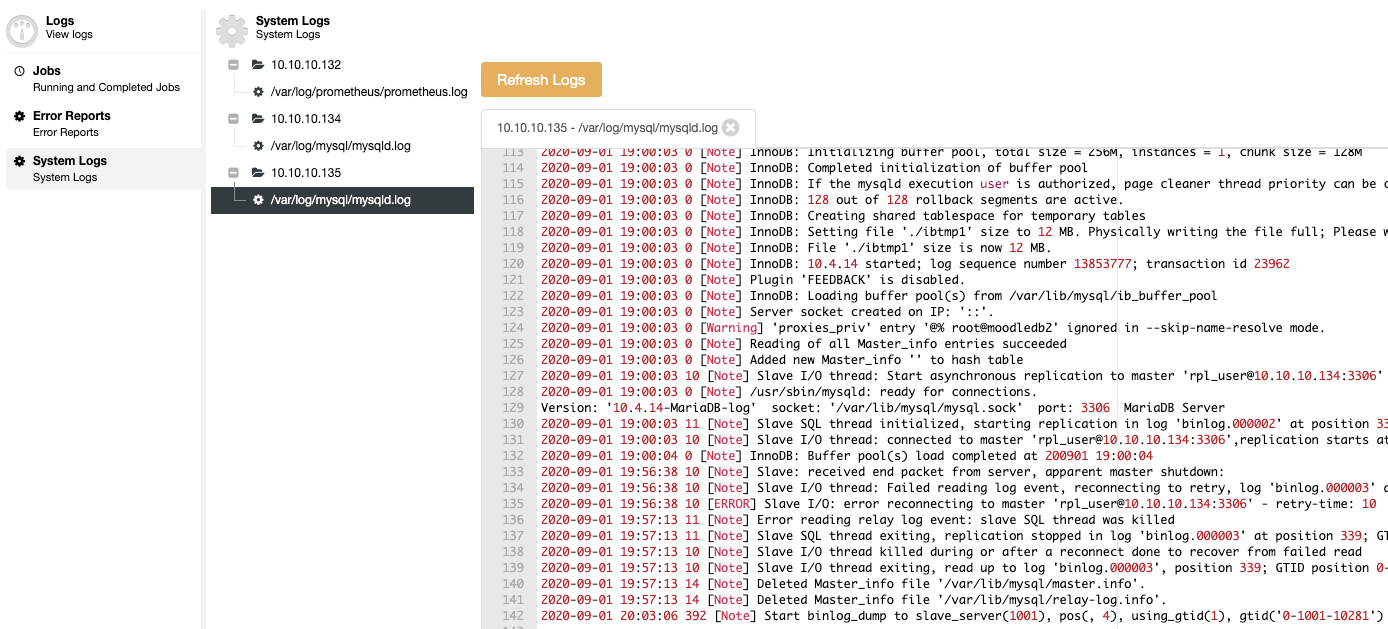
As you can see, you can handle all the mentioned things from the same centralized system: ClusterControl.
Managing and Monitoring with the ClusterControl Command Line
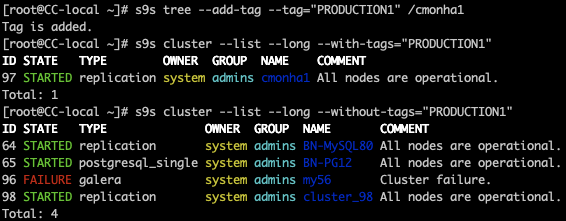
For scripting and automating tasks, or even if you just prefer the command line, ClusterControl has the s9s tool. It is a command-line tool for managing your database cluster.
Cluster List
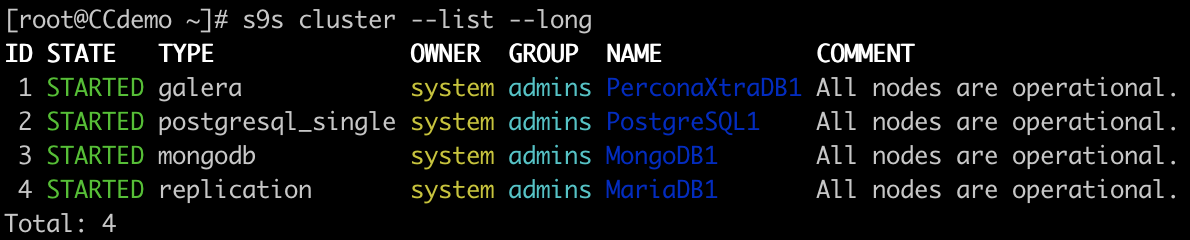
Node List
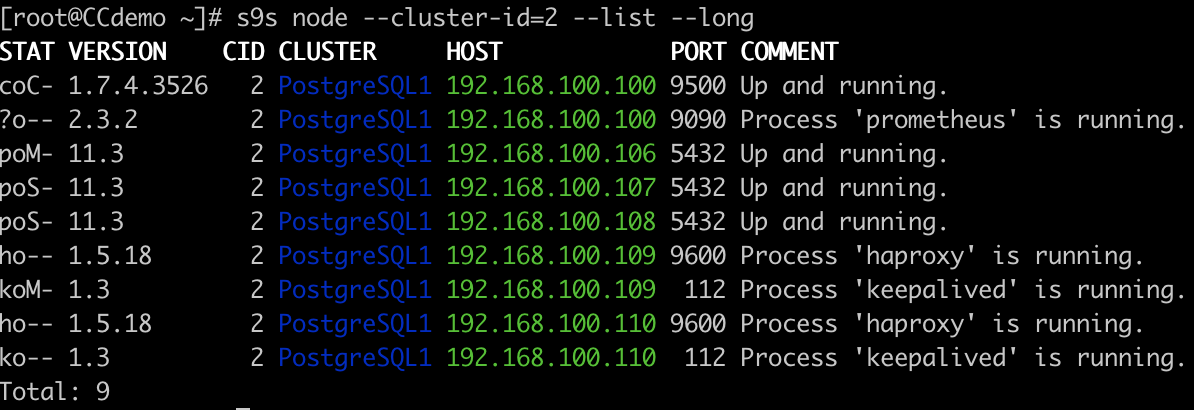
You can perform all the tasks that you are able to see in the ClusterControl UI (and even more), and you can integrate this feature with some external tools like slack, to manage it from there.
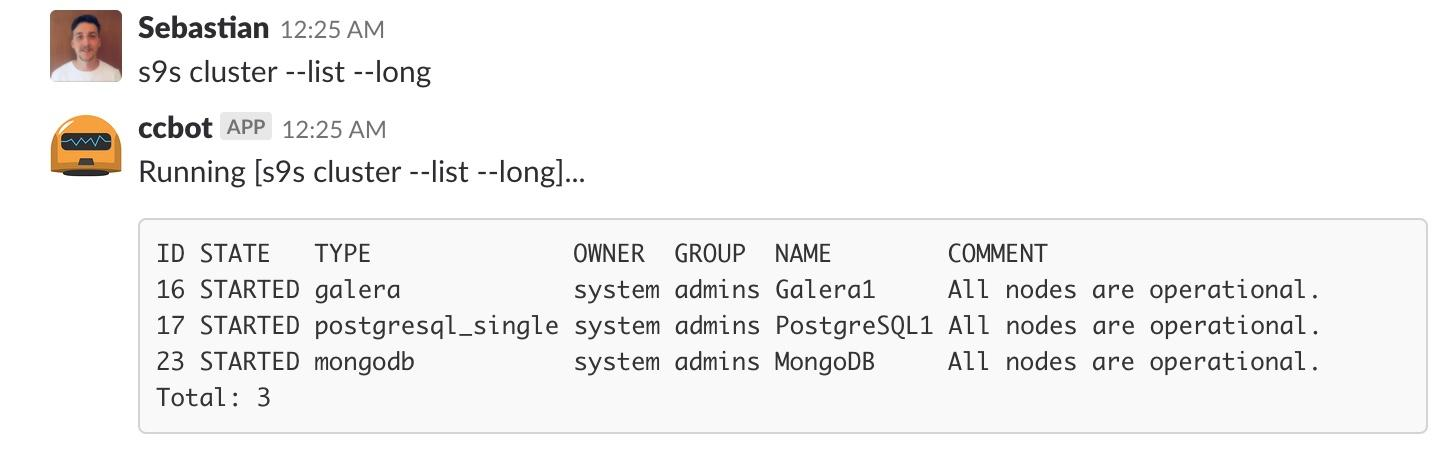
Conclusion
In this blog, we mentioned some important metrics to monitor in your Moodle Database, and some management tasks useful to keep your system running. Managing and Monitoring your Moodle Database is necessary but also a time-consuming task if you don’t have any tools to help with this.
For this, we also show how ClusterControl can make your life easier by using the main managing and monitoring features.