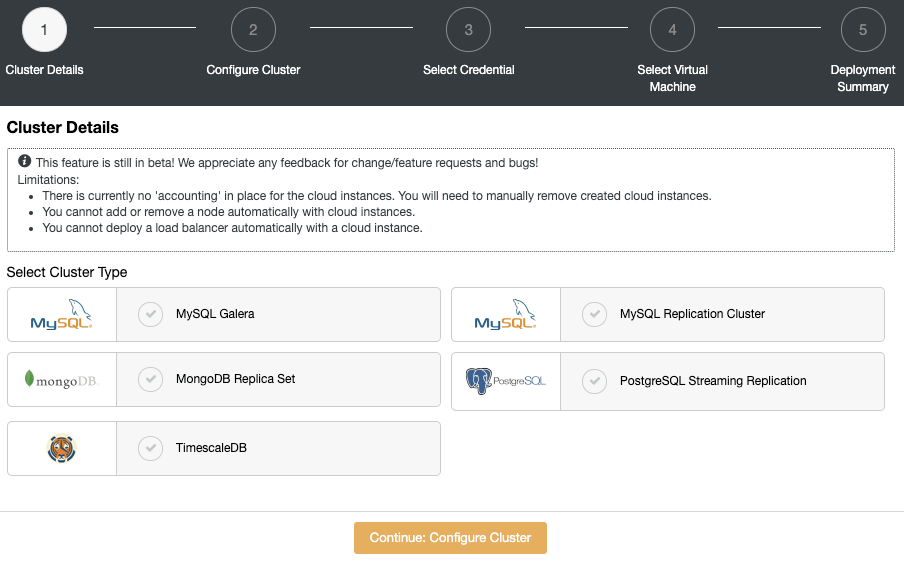
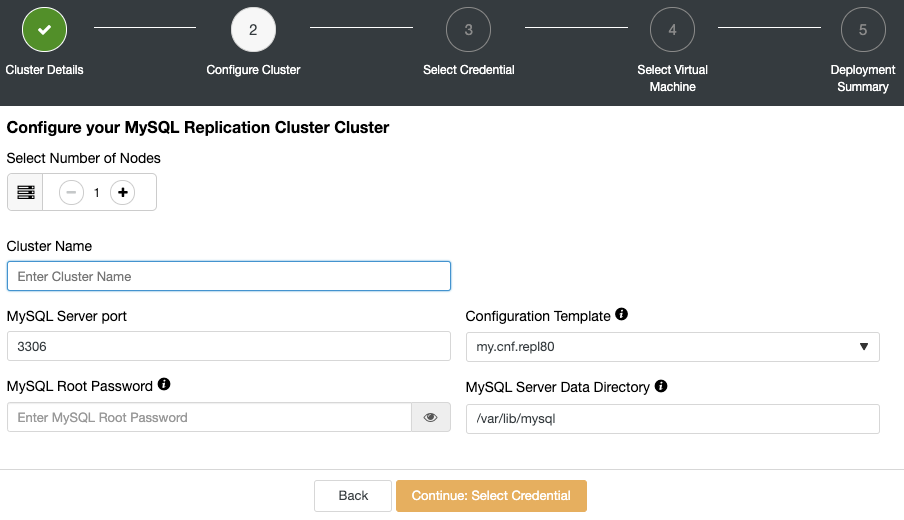
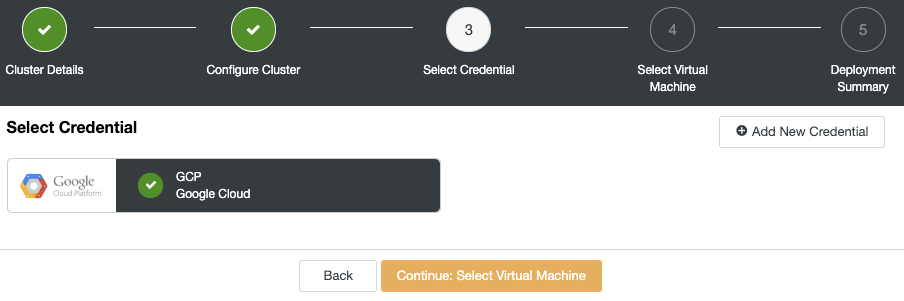
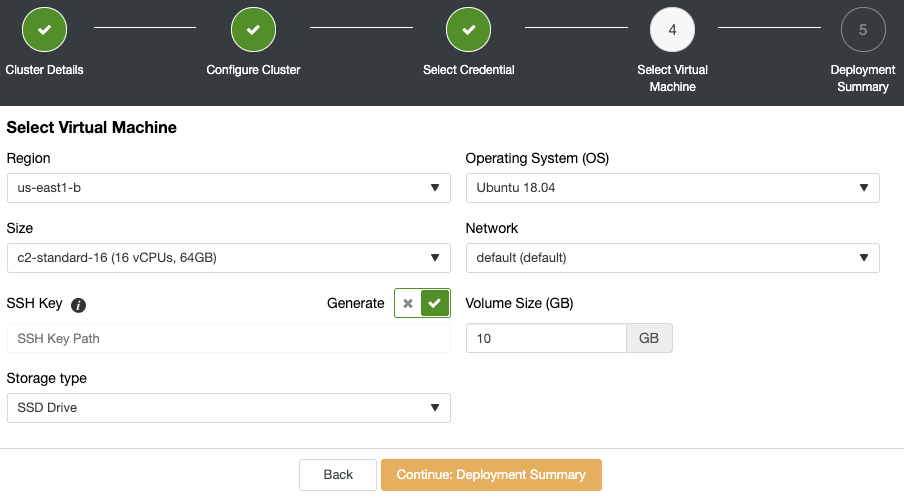
ClusterControl consists of a number of components and one of the most important ones is the ClusterControl UI. This is the web application through which the user interacts with other backend ClusterControl components like controller, notification, web-ssh module and cloud module. Each component is packaged independently with its own name, therefore easier for potential issues to be fixed and delivered to the end user. For more info on ClusterControl components, check out the documentation page.
In this blog post, we are going to look into ways to customize our ClusterControl installation, especially the ClusterControl UI which by default will be located under /var/www/html (default document root of Apache). Note that it's recommended to host ClusterControl on a dedicated server where it can use all the default paths which will simplify ClusterControl maintenance operations.
Installing ClusterControl
For a fresh installation, go to our Download page to get the installation link. Then, start installing ClusterControl using the installer script as root user:
$ whoami
root
$ wget https://severalnines.com/downloads/cmon/install-cc
$ chmod 755 install-cc
$ ./install-ccFollow the installation wizard accordingly and the script will install all dependencies, configure ClusterControl components and start them up. The script will configure Apache 2.4, and use the package manager to install ClusterControl UI which by default located under /var/www/html.
Preparation
Once ClusterControl is installed into its default location, we can then move the UI directories located under /var/www/html/clustercontrol and /var/www/html/cmon into somewhere else. Let's prepare the new path first.
Suppose we want to move the UI components to a user directory under /home. Firstly, create the user. In this example, the user name is "cc":
$ useradd -m ccThe above command will automatically create a home directory for user "cc", under /home/cc. Then, create the necessary directories for Apache usage for this user. We are going to create a directory called "logs" for Apache logs, "public_html" for Apache document root of this user and the "www" as a symbolic link to the public_html:
$ cd /home/cc
$ mkdir logs
$ mkdir public_html
$ ln -sf public_html wwwMake sure all of them are owned by Apache:
$ chown apache:apache logs public_htmlTo allow Apache process to access public_html under user cc, we have to allow global read to the home directory of user cc:
$ chmod 755 /home/ccWe are now good to move stuff.
Customizing the Path
Stop ClusterControl related services and Apache:
$ systemctl stop httpd # RHEL/CentOS
$ systemctl stop apache2 # Debian/Ubuntu
$ systemctl stop cmon cmon-events cmon-ssh cmon-cloudWe basically have two options in moving the directory into the user's directory:
- Move everything from /var/www/html into /home/cc/public_html.
- Create a symbolic link from /var/www/html/clustercontrol to /home/cc/public_html (recommended).
If you opt for option #1, simply move the ClusterControl UI directories into the new path,/home/cc/public_html:
$ mv /var/www/html/clustercontrol /home/cc/public_html/
$ mv /var/www/html/cmon /home/cc/public_html/Make sure the ownership is correct:
$ chown -R apache:apache /home/cc/public_html # RHEL/CentOS
$ chown -R www-data:www-data /home/cc/public_html # Debian/UbuntuHowever, there is a drawback since ClusterControl UI package will always get extracted under /var/www/html. This means if you upgrade the ClusterControl UI via package manager, the new content will be available under /var/www/html. Refer to "Potential Issues" section further down for more details.
If you choose option #2, which is the recommended way, you just need to create a symlink (link reference to another file or directory) under the user's public_html directory for both directories. When an upgrade happens, the DEB/RPM postinst script will replace the existing installation with the updated version under /var/www/html. To do a symlink, simply:
$ ln -sf /var/www/html/clustercontrol /home/cc/public_html/clustercontrol
$ ln -sf /var/www/html/cmon /home/cc/public_html/cmonAnother step is required for option #2, where we have to allow Apache to follow symbolic links outside of the user's directory. Create a .htaccess file under /home/cc/public_html and add the following line:
# /home/cc/public_html/.htaccess
Options +FollowSymlinks -SymLinksIfOwnerMatchOpen Apache site configuration file at /etc/httpd/conf.d/s9s.conf (RHEL/CentOS) or /etc/apache2/sites-enabled/001-s9s.conf (Debian/Ubuntu) using your favourite text editor and modify it to be as below (pay attention on lines marked with ##):
<VirtualHost *:80>
ServerName cc.domain.com ##
ServerAdmin webmaster@cc.domain.com
DocumentRoot /home/cc/public_html ##
ErrorLog /home/cc/logs/error.log ##
CustomLog /home/cc/logs/access.log combined ##
# ClusterControl SSH & events
RewriteEngine On
RewriteRule ^/clustercontrol/ssh/term$ /clustercontrol/ssh/term/ [R=301]
RewriteRule ^/clustercontrol/ssh/term/ws/(.*)$ ws://127.0.0.1:9511/ws/$1 [P,L]
RewriteRule ^/clustercontrol/ssh/term/(.*)$ http://127.0.0.1:9511/$1 [P]
RewriteRule ^/clustercontrol/sse/events/(.*)$ http://127.0.0.1:9510/events/$1 [P,L]
# Main Directories
<Directory />
Options +FollowSymLinks
AllowOverride All
</Directory>
<Directory /home/cc/public_html> ##
Options +Indexes +FollowSymLinks +MultiViews
AllowOverride All
Require all granted
</Directory>
</VirtualHost>The similar modifications apply to the HTTPS configuration at /etc/httpd/conf.d/ssl.conf (RHEL/CentOS) or /etc/apache2/sites-enabled/001-s9s-ssl.conf (Debian/Ubuntu). Pay attention to lines marked with ##:
<IfModule mod_ssl.c>
<VirtualHost _default_:443>
ServerName cc.domain.com ##
ServerAdmin webmaster@cc.domain.com ##
DocumentRoot /home/cc/public_html ##
# ClusterControl SSH & events
RewriteEngine On
RewriteRule ^/clustercontrol/ssh/term$ /clustercontrol/ssh/term/ [R=301]
RewriteRule ^/clustercontrol/ssh/term/ws/(.*)$ ws://127.0.0.1:9511/ws/$1 [P,L]
RewriteRule ^/clustercontrol/ssh/term/(.*)$ http://127.0.0.1:9511/$1 [P]
RewriteRule ^/clustercontrol/sse/events/(.*)$ http://127.0.0.1:9510/events/$1 [P,L]
<Directory />
Options +FollowSymLinks
AllowOverride All
</Directory>
<Directory /home/cc/public_html> ##
Options +Indexes +FollowSymLinks +MultiViews
AllowOverride All
Require all granted
</Directory>
SSLEngine on
SSLCertificateFile /etc/pki/tls/certs/s9server.crt # RHEL/CentOS
SSLCertificateKeyFile /etc/pki/tls/private/s9server.key # RHEL/CentOS
SSLCertificateKeyFile /etc/ssl/certs/s9server.crt # Debian/Ubuntu
SSLCertificateKeyFile /etc/ssl/private/s9server.key # Debian/Ubuntu
<FilesMatch "\.(cgi|shtml|phtml|php)$">
SSLOptions +StdEnvVars
</FilesMatch>
<Directory /usr/lib/cgi-bin>
SSLOptions +StdEnvVars
</Directory>
BrowserMatch "MSIE [17-9]" ssl-unclean-shutdown
</VirtualHost>
</IfModule>Restart everything:
$ systemctl restart httpd
$ systemctl restart cmon cmon-events cmon-ssh cmon-cloudConsider the IP address of the ClusterControl is 192.168.1.202 and domain cc.domain.com resolves to 192.168.1.202, you can access ClusterControl UI via one of the following URLs:
- http://192.168.1.202/clustercontrol
- https://192.168.1.202/clustercontrol
- http://cc.domain.com/clustercontrol
- https://cc.domain.com/clustercontrol
You should see the ClusterControl login page at this point. The customization is now complete.
Potential Issues
Since the package manager simply executes the post-installation script during package upgrade, the content of the new ClusterControl UI package (the actual package name is clustercontrol.x86_64) will be extracted into /var/www/html (it's hard coded inside post installation script). The following is what would happen:
$ ls -al /home/cc/public_html # our current installation
clustercontrol
cmon
$ ls -al /var/www/html # empty
$ yum upgrade clustercontrol -y
$ ls -al /var/www/html # new files are extracted here
clustercontrol
cmonTherefore, if you use symlink method, you may skip the following additional steps.
To complete the upgrade process, one has to replace the existing installation under the custom path with the new installation manually. First, perform the upgrade operation:
$ yum upgrade clustercontrol -y # RHEL/CentOS
$ apt upgrade clustercontrol -y # Debian/UbuntuMove the existing installation to somewhere safe. We will need the old bootstrap.php file later on:
$ mv /home/cc/public_html/clustercontrol /home/cc/public_html/clustercontrol_oldMove the new installation from the default path /var/www/html into user's document root:
$ mv /var/www/html/clustercontrol /home/cc/public_htmlCopy bootstrap.php from the old installation to the new one:
$ mv /home/cc/public_html/clustercontrol_old/bootstrap.php /home/cc/public_html/clustercontrolGet the new version string from bootstrap.php.default:
$ grep CC_UI_VERSION /home/cc/public_html/clustercontrol/bootstrap.php.default
define('CC_UI_VERSION', '1.7.4.6537-#f427cb');Update the new version string for CC_UI_VERSION value inside bootstrap.php using your favourite text editor:
$ vim /home/cc/public_html/clustercontrol/bootstrap.phpSave the file and the upgrade is now complete.
That's it, folks. Happy customizing!