Monitoring your MySQL database proactively is imperative nowadays. It plays a crucial and significant part for managing and controlling your database especially for your production-grade clusters. Missing specific information that would be beneficial for improving your database or failing to identif the root cause for problems that can be encountered might produce extreme difficulty to fix or recover from its glory days.
Proactive monitoring in your MySQL database allows your team to understand how your database services are performing. Does it function and deliver based on the workload it is expected to carry? Do you have enough resources for the server to be performant based on the workload that it is currently handling? Proactive monitoring applies things that shall prevent disaster or from harming your database which shall notify you in advance. Thus, allowing the DBAs or administrators to perform important tasks to avoid encountering malfunctions, data corruption, security exploits and attacks, or unexpected bounce of traffic in your database cluster. By these being attended immediately, proactive monitoring for MySQL has to be automated and shall operate 24/7 without interruption and it's up to the DBAs, Devops, administrators to decide whether based on priority of tasks and how crucial it is if it requires maintenance or just a typical daily routine work.
Proactive monitoring with ClusterControl
ClusterControl offers a diverse style for monitoring your MySQL database servers. Its approach is comparable to other enterprise monitoring tools and to enterprise-grade cloud solutions. ClusterControl tends to apply all the best practices for managing and monitoring the databases but with the flexibility to configure in order to achieve the desired setup based in your environment.
When it comes to alarms and notifications, ClusterControl has a mixed approach for which there are built-in alarms, and then there's the Advisors for which we'll discuss more over on this blog.
ClusterControl Alarms for MySQL
Alarms indicate problems that could affect or degrade the cluster as a whole. This interface provides a detailed explanation on the problem, together with the recommended action (if available) to resolve the problem. Each alarm is categorized as:
Cluster
Cluster recovery
Database health
Database performance
Host
Node
Network
An alarm can be acknowledged by checking the Ignore? checkbox. When ignored, no notification will be sent via email. An alarm cannot be deleted or dismissed, though you can hide it from the list by clicking on Hide Ignored Alarms button.
See example screenshot below,
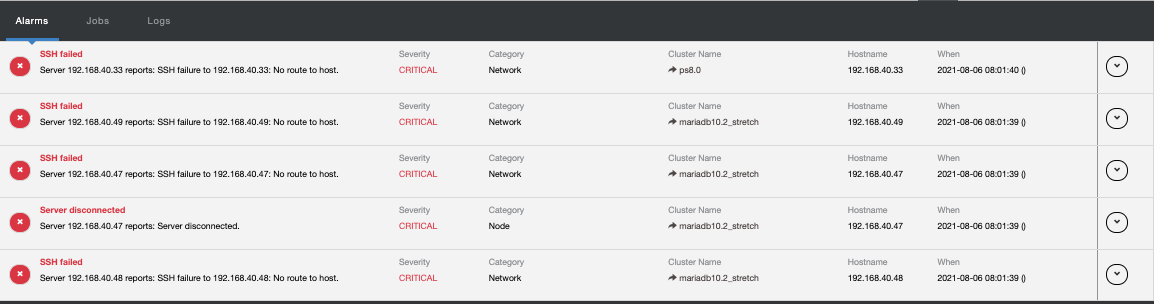
Proactivity with ClusterControl
ClusterControl supports auto recovery which reacts whenever a failure detection has occurred. Auto Recovery with ClusterControl is one of the most proactive functionalities that plays a crucial role in the event of disasters.
Enabling the auto recovery is required for this proactive monitoring which reacts in various situations, for example, if the primary MySQL node fails.

In ClusterControl, this will be detected right away as it listens to the connection with the database server, or in this case the primary server. ClusterControl will react ASAP and apply a failover.
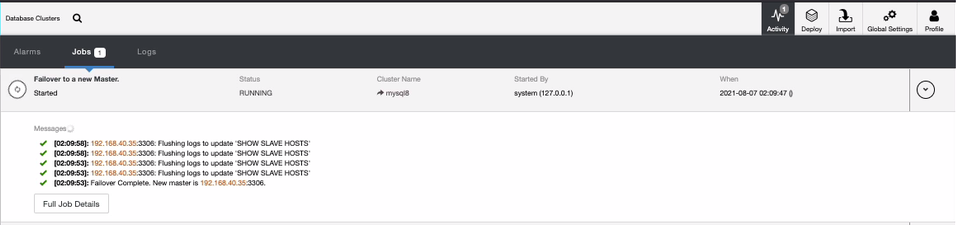
The failover is part of the enabled Cluster recovery. Since both buttons Cluster and Node are enabled, then it follows the node recovery as you see below.
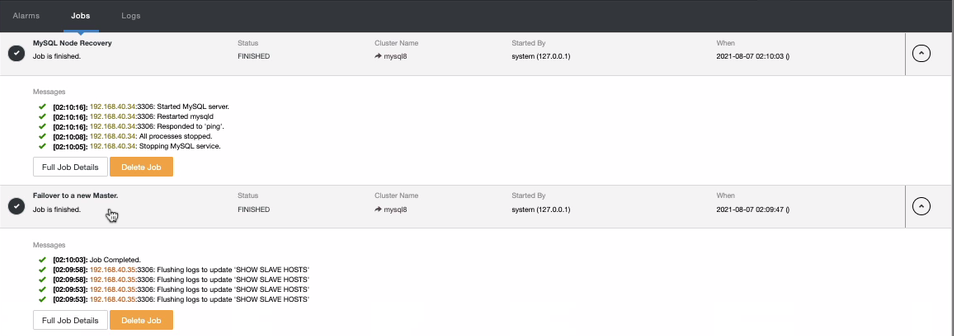
Depending on the reachability of the nodes, ClusterControl will try to continuously attempt by connecting through SSH and try to reach the node and attempt to recover by starting using sysvinit or systemd. Obviously, you might think that it applies a failover and ClusterControl tries to start the failed primary. That could mean two database nodes are available, right? Although true, ClusterControl will take the failed primary to a read-only state while being recovered. See below,
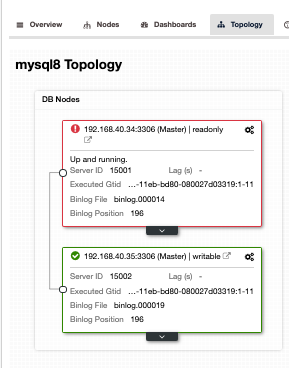
Although there are certain options you can set to manage the failover mechanism, you should refer to our documentation for this since it is not the focus of this blog.
Using Advisors for Proactivity with ClusterControl
In ClusterControl, Advisors will be located by going to <Select Your MySQL Cluster> → Performance → Advisors. ClusterControl advisors are set to be applied depending on the cluster it is trying to monitor. For example, a MySQL Replication and MySQL with Galera Cluster running either on Percona or MariaDB can have differences. For example, the MySQL Replication Advisors have the following,

While in a Galera Cluster, it adds the Galera specific advisors as shown below,

Customizing your ClusterControl MySQL Advisors
Advisors are customizable and can be modified in accordance to your needs. In the Advisors' screenshot above, just click Edit and you'll be redirected to the simple IDE we have built-in in ClusterControl.

You can also create your own ClusterControl Advisors. You can refer yourself to learn more about creating by reading Write Your First Advisor or take the 2-part series to create your own using Meltdown/Spectre detection script.
How Are ClusterControl Advisors Being Proactive?
Technically, ClusterControl advisors mostly act as a notifier and literally your advisors. ClusterControl Advisors will notify you if it detects unusual behavior if it reaches over the base thresholds set by default by ClusterControl. Usually, the thresholds applied are generic values. These generic values are based on best practices and on the most common and acceptable workload or environment setup. Most of the advisors' default does not provide alarms or alert mechanisms in the ClusterControl UI. It does notify you via the UI (see sample screenshot of the Binlog Storage Location advisor below).
As mentioned earlier, Advisors can be modified and are editable via our simple editor or IDE. For example in a MySQL Replication cluster, ClusterControl provides a Binlog Storage Location advisor. It detects that binlogs are stored in the data directory where it advises that it must be outside the data directory.

Let's take an example from the list of advisors and select Connections currently used advisor. Let's edit this as shown below,

or alternatively, you can go over to <Select Your MySQL Cluster> → Manage → Developer Studio and select the connections_used_pct.js as shown below.
By making it more proactive by sending alarms, you can modify it and add the following functions just like below,
function myAlarm(title, message, recommendation)
{
return Alarm::alarmId(
Node,
true,
title,
message,
recommendation
);
}Whereas, setting the threshold to 20 then add these lines below just within the if condition statement where threshold is reached above its given threshold value.
myAlarmId = myAlarm(TITLE, msg, ADVICE_WARNING);
// Let's raise an alarm.
host.raiseAlarm(myAlarmId, Warning);
Here's the complete script with my modifications in bold,
#include "common/mysql_helper.js"
var DESCRIPTION="This advisor calculates the percentage of threads_connected over max_connections,"" if the percentage is higher than 20% you will be notified,"" preventing your database server from becoming unstable.";
var WARNING_THRESHOLD=20;
var TITLE="Connections currently used";
var ADVICE_WARNING="You are using more than " + WARNING_THRESHOLD +
"% of the max_connections."" Consider regulating load, e.g by using HAProxy. Using up all connections"" may render the database server unusable.";
var ADVICE_OK="The percentage of currently used connections is satisfactory." ;
function myAlarm(title, message, recommendation)
{
return Alarm::alarmId(
Node,
true,
title,
message,
recommendation
);
}
function main()
{
var hosts = cluster::mySqlNodes();
var advisorMap = {};
for (idx = 0; idx < hosts.size(); ++idx)
{
host = hosts[idx];
map = host.toMap();
connected = map["connected"];
var advice = new CmonAdvice();
print("");
print(host);
print("==========================");
if (!connected)
{
print("Not connected");
continue;
}
var Threads_connected = host.sqlStatusVariable("Threads_connected");
var Max_connections = host.sqlSystemVariable("Max_connections");
if (Threads_connected.isError() || Max_connections.isError())
{
justification = "";
msg = "Not enough data to calculate";
}
else
{
var used = round(100 * Threads_connected / Max_connections,1);
if (used > WARNING_THRESHOLD)
{
advice.setSeverity(1);
msg = ADVICE_WARNING;
justification = used + "% of the connections is currently used,"" which is > " + WARNING_THRESHOLD + "% of max_connections.";
myAlarmId = myAlarm(TITLE, msg, ADVICE_WARNING);
// Let's raise an alarm.
host.raiseAlarm(myAlarmId, Warning);
}
else
{
justification = used + "% of the connections is currently used,"" which is < 90% of max_connections.";
advice.setSeverity(0);
msg = ADVICE_OK;
}
}
advice.setHost(host);
advice.setTitle(TITLE);
advice.setJustification(justification);
advice.setAdvice(msg);
advisorMap[idx]= advice;
print(advice.toString("%E"));
}
return advisorMap;
}You can use sysbench to test it. In my test, I am proactively notified by sending the alarm. This shall also be sent to me via email or can be notified if you have integrated third party notifications. See the screenshot below,

ClusterControl’s Advisors Caveats
Modifying or editing an existing advisor in ClusterControl is applied to all clusters. That means, you need to check in your script if it has a specific condition applicable only for your existing cluster (either MySQL or other supported databases by ClusterControl). This is because the ClusterControl advisors are stored in a single source only via our cmon DB. These are pulled or retrieved by all clusters you have created in ClusterControl.
For example, you can do this in a script:
var hosts = cluster::mySqlNodes();
var advisorMap = {};
print(hosts[1].clusterId());
This script will print the cluster ID. Once you get the value, assign it to a variable and use that variable to evaluate if it's true that this specific cluster ID is acceptable or not based on your desired task to be done by your advisor. Let say,
function main()
{
var hosts = cluster::mySqlNodes();
var advisorMap = {};
for (idx = 0; idx < hosts.size(); ++idx)
{
host = hosts[idx];
map = host.toMap();
connected = map["connected"];
var advice = new CmonAdvice();
print("");
print(host);
print("==========================");
if (host.clusterId() == 15)
{
print("Not applicable for cluster id == 15");
continue;
}
…
….
…..which means if it's the cluster_id == 15, then just skip or continue to the next loop.
Conclusion
Creating or modifying the ClusterControl Advisors is a good opportunity to leverage the hidden functionality that ClusterControl can provide you. It might appear to be hidden but it's there - it’s just that the feature is used less. It provides simple but a powerful feature called ClusterControl Domain Specific Language (CDSL) which can be used for extremely difficult tasks that ClusterControl lacks. Just make sure you know all of the caveats and also do test everything first before finally applying it to your production environment.