In the first part, we ended up with a working cmon HA cluster:
root@vagrant:~# s9s controller --list --long
S VERSION OWNER GROUP NAME IP PORT COMMENT
l 1.7.4.3565 system admins 10.0.0.101 10.0.0.101 9501 Acting as leader.
f 1.7.4.3565 system admins 10.0.0.102 10.0.0.102 9501 Accepting heartbeats.
f 1.7.4.3565 system admins 10.0.0.103 10.0.0.103 9501 Accepting heartbeats.
Total: 3 controller(s)We have three nodes up and running, one is acting as a leader and remaining are followers, which are accessible (they do receive heartbeats and reply to them). The remaining challenge is to configure UI access in a way that will allow us to always access the UI on the leader node. In this blog post we will present one of the possible solutions which will allow you to accomplish just that.
Setting up HAProxy
This problem is not new to us. With every replication cluster, MySQL or PostgreSQL, it doesn’t matter, there’s a single node where we should send our writes to. One way of accomplishing that would be to use HAProxy and add some external checks that test the state of the node, and based on that, return proper values. This is basically what we are going to use to solve our problem. We will use HAProxy as a well-tested layer 4 proxy and we will combine it with layer 7 HTTP checks that we will write precisely for our use case. First things first, let’s install HAProxy. We will collocate it with ClusterControl, but it can as well be installed on a separate node (ideally, nodes - to remove HAProxy as the single point of failure).
apt install haproxyThis sets up HAProxy. Once it’s done, we have to introduce our configuration:
global
pidfile /var/run/haproxy.pid
daemon
user haproxy
group haproxy
stats socket /var/run/haproxy.socket user haproxy group haproxy mode 600 level admin
node haproxy_10.0.0.101
description haproxy server
#* Performance Tuning
maxconn 8192
spread-checks 3
quiet
defaults
#log global
mode tcp
option dontlognull
option tcp-smart-accept
option tcp-smart-connect
#option dontlog-normal
retries 3
option redispatch
maxconn 8192
timeout check 10s
timeout queue 3500ms
timeout connect 3500ms
timeout client 10800s
timeout server 10800s
userlist STATSUSERS
group admin users admin
user admin insecure-password admin
user stats insecure-password admin
listen admin_page
bind *:9600
mode http
stats enable
stats refresh 60s
stats uri /
acl AuthOkay_ReadOnly http_auth(STATSUSERS)
acl AuthOkay_Admin http_auth_group(STATSUSERS) admin
stats http-request auth realm admin_page unless AuthOkay_ReadOnly
#stats admin if AuthOkay_Admin
listen haproxy_10.0.0.101_81
bind *:81
mode tcp
tcp-check connect port 80
timeout client 10800s
timeout server 10800s
balance leastconn
option httpchk
# option allbackups
default-server port 9201 inter 20s downinter 30s rise 2 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:443 check
server 10.0.0.102 10.0.0.102:443 check
server 10.0.0.103 10.0.0.103:443 checkYou may want to change some of the things here like the node or backend names which include here the IP of our node. You will definitely want to change servers that you are going to have included in your HAProxy.
The most important bits are:
bind *:81HAProxy will listen on port 81.
option httpchkWe have enabled layer 7 check on the backend nodes.
default-server port 9201 inter 20s downinter 30s rise 2 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100The layer 7 check will be executed on port 9201.
Once this is done, start HAProxy.
Setting up xinetd and Check Script
We are going to use xinetd to execute the check and return correct responses to HAProxy. Steps described in this paragraph should be executed on all cmon HA cluster nodes.
First, install xinetd:
root@vagrant:~# apt install xinetdOnce this is done, we have to add the following line:
cmonhachk 9201/tcpto /etc/services - this will allow xinetd to open a service that will listen on port 9201. Then we have to add the service file itself. It should be located in /etc/xinetd.d/cmonhachk:
# default: on
# description: cmonhachk
service cmonhachk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/cmonhachk.py
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITED
}Finally, we need the check script that’s called by the xinetd. As defined in the service file it is located in /usr/local/sbin/cmonhachk.py.
#!/usr/bin/python3.5
import subprocess
import re
import sys
from pathlib import Path
import os
def ret_leader():
leader_str = """HTTP/1.1 200 OK\r\n
Content-Type: text/html\r\n
Content-Length: 48\r\n
\r\n
<html><body>This node is a leader.</body></html>\r\n
\r\n"""
print(leader_str)
def ret_follower():
follower_str = """
HTTP/1.1 503 Service Unavailable\r\n
Content-Type: text/html\r\n
Content-Length: 50\r\n
\r\n
<html><body>This node is a follower.</body></html>\r\n
\r\n"""
print(follower_str)
def ret_unknown():
unknown_str = """
HTTP/1.1 503 Service Unavailable\r\n
Content-Type: text/html\r\n
Content-Length: 59\r\n
\r\n
<html><body>This node is in an unknown state.</body></html>\r\n
\r\n"""
print(unknown_str)
lockfile = "/tmp/cmonhachk_lockfile"
if os.path.exists(lockfile):
print("Lock file {} exists, exiting...".format(lockfile))
sys.exit(1)
Path(lockfile).touch()
try:
with open("/etc/default/cmon", 'r') as f:
lines = f.readlines()
pattern1 = "RPC_BIND_ADDRESSES"
pattern2 = "[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}"
m1 = re.compile(pattern1)
m2 = re.compile(pattern2)
for line in lines:
res1 = m1.match(line)
if res1 is not None:
res2 = m2.findall(line)
i = 0
for r in res2:
if r != "127.0.0.1" and i == 0:
i += 1
hostname = r
command = "s9s controller --list --long | grep {}".format(hostname)
output = subprocess.check_output(command.split())
state = output.splitlines()[1].decode('UTF-8')[0]
if state == "l":
ret_leader()
if state == "f":
ret_follower()
else:
ret_unknown()
finally:
os.remove(lockfile)Once you create the file, make sure it is executable:
chmod u+x /usr/local/sbin/cmonhachk.pyThe idea behind this script is that it tests the status of the nodes using “s9s controller --list --long” command and then it checks the output relevant to the IP that it can find on the local node. This allows the script to determine if the host on which it is executed is a leader or not. If the node is the leader, script returns “HTTP/1.1 200 OK” code, which HAProxy interprets as the node is available and routes the traffic to it.. Otherwise it returns “HTTP/1.1 503 Service Unavailable”, which is treated as a node, which is not healthy and the traffic will not be routed there. As a result, no matter which node will become a leader, HAProxy will detect it and mark it as available in the backend:
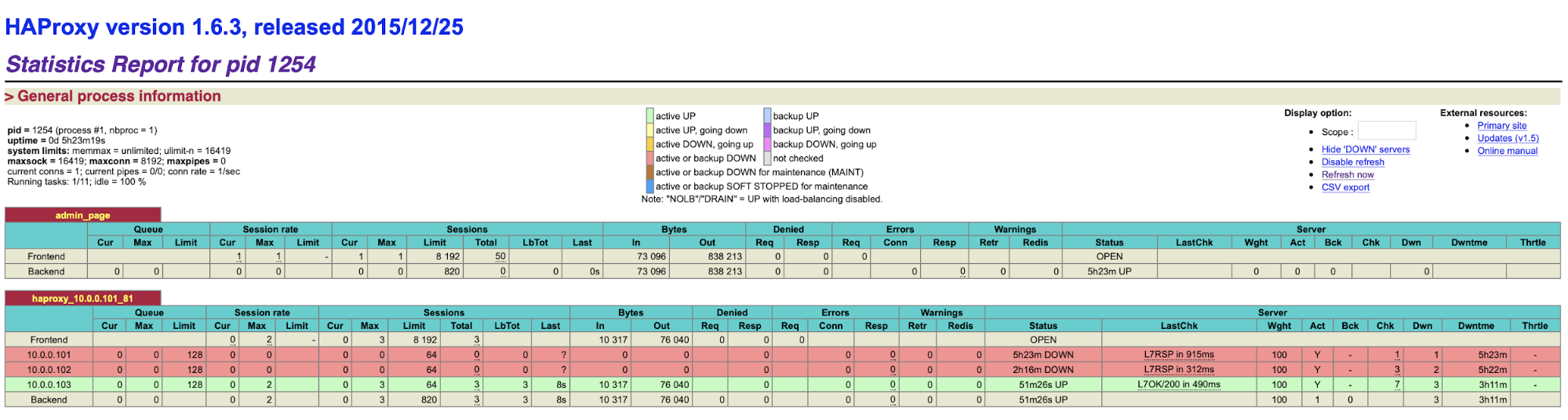
You may need to restart HAProxy and xinetd to apply configuration changes before all the parts will start working correctly.
Having more than one HAProxy ensures we have a way to access ClusterControl UI even if one of HAProxy nodes would fail but we still have two (or more) different hostnames or IP to connect to the ClusterControl UI. To make it more comfortable, we will deploy Keepalived on top of HAProxy. It will monitor the state of HAProxy services and assign Virtual IP to one of them. If that HAProxy would become unavailable, VIP will be moved to another available HAProxy. As a result, we’ll have a single point of entry (VIP or a hostname associated to it). The steps we’ll take here have to be executed on all of the nodes where HAProxy has been installed.
First, let’s install keepalived:
apt install keepalivedThen we have to configure it. We’ll use following config file:
vrrp_script chk_haproxy {
script "killall -0 haproxy" # verify the pid existance
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}
vrrp_instance VI_HAPROXY {
interface eth1 # interface to monitor
state MASTER
virtual_router_id 51 # Assign one ID for this route
priority 102
unicast_src_ip 10.0.0.101
unicast_peer {
10.0.0.102
10.0.0.103
}
virtual_ipaddress {
10.0.0.130 # the virtual IP
}
track_script {
chk_haproxy
}
# notify /usr/local/bin/notify_keepalived.sh
}You should modify this file on different nodes. IP addresses have to be configured properly and priority should be different on all of the nodes. Please also configure VIP that makes sense in your network. You may also want to change the interface - we used eth1, which is where the IP is assigned on virtual machines created by Vagrant.
Start the keepalived with this configuration file and you should be good to go. As long as VIP is up on one HAProxy node, you should be able to use it to connect to the proper ClusterControl UI:

This completes our two-part introduction to ClusterControl highly available clusters. As we stated at the beginning, this is still in beta state but we are looking forward for feedback from your tests.