Ensuring smooth operations of your production databases is not a trivial task, and there are a number of tools and utilities to help with the job. There are tools available for monitoring health, server performance, analyzing queries, deployments, managing failover, upgrades, and the list goes on. ClusterControl as a management and monitoring platform for your database infrastructure stands out with its ability to manage the full lifecycle from deployment to monitoring, ongoing management and scaling.
Although ClusterControl offers important features like automatic database failover, encryption in-transit/at-rest, backup management, point-in-time recovery, Prometheus integration, database scaling, these can be found in other enterprise management/monitoring tools on the market. However, there are some features that you won’t find that easily. In this blog post, we’ll present 9 features that you won't find in any other management and monitoring tools on the market (as the time of this writing).
Backup Verification
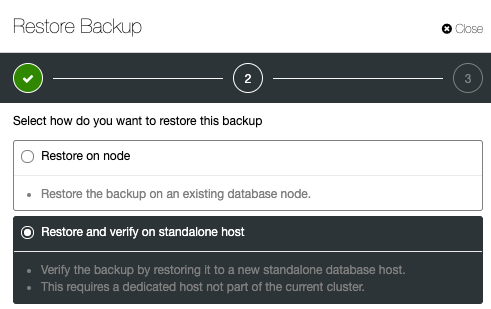
Any backup is literally not a backup until you know it can be recovered - by really verifying that it can be recovered. ClusterControl allows a backup to be verified after the backup has been taken by spinning a new server and testing restore. Verifying a backup is a critical process to make sure you meet your Recovery Point Objective (RPO) policy in the event of disaster recovery. The verification process will perform the restoration on a new standalone host (where ClusterControl will install necessary database packages before restoring) or on a server dedicated for backup verification.
To configure backup verification, simply select an existing backup and click on Restore. There will be an option to Restore and Verify:
Then, simply specify the IP address of the server that you would want to restore and verify:
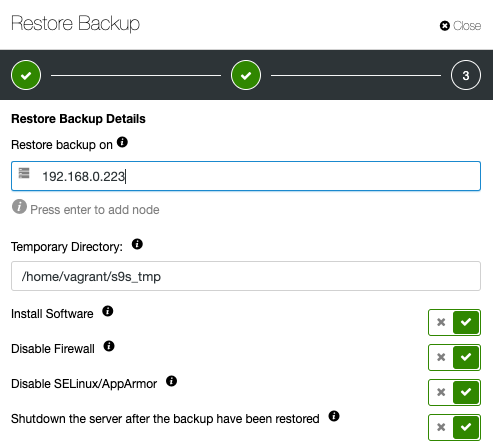
Make sure the specified host is accessible via passwordless SSH beforehand. You also have a handful of options underneath for provisioning process. You can also shutdown the verification server after restoration to save costs and resources after the backup has been verified. ClusterControl will look for the restoration process exit code and observe the restore log to check whether the verification fails or succeeds.
Simplifying ProxySQL Management Through a GUI
Many would agree that having a graphical user interface is more efficient and less prone to human error when configuring a system. ProxySQL is a part of the critical database layer (although it sits on top of it) and must be visible enough to DBA's eyes to spot common problems and issues. ClusterControl provides a comprehensive graphical user interface for ProxySQL.
ProxySQL instances can be deployed on fresh hosts, or existing ones can be imported into ClusterControl. ClusterControl can configure ProxySQL to be integrated with a virtual IP address (provided by Keepalived) for single endpoint access to the database servers. It also provides monitoring insight to the key ProxySQL components like Queries Backend, Slow Queries, Top Queries, Query Hits, and a bunch of other monitoring stats. The following is a screenshot showing how to add a new query rule:
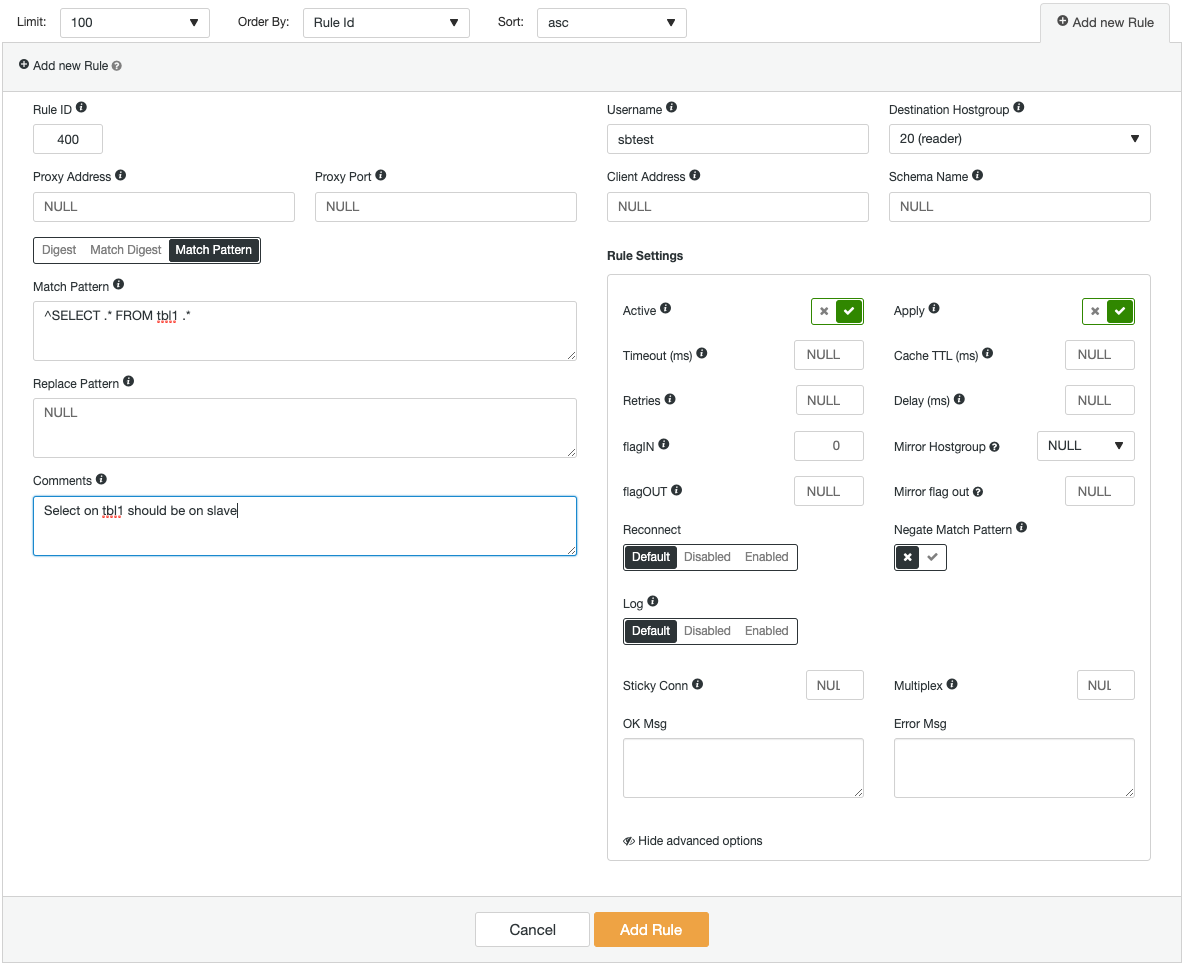
If you were adding a very complex query rule, you would be more comfortable doing it via the graphical user interface. Every field has a tooltip to assist you when filling in the Query Rule form. When adding or modifying any ProxySQL configuration, ClusterControl will make sure the changes are made to runtime, and saved onto disk for persistency.
ClusterControl 1.7.4 now supports both ProxySQL 1.x and ProxySQL 2.x.
Operational Reports
Operational Reports are a set of summary reports of your database infrastructure that can be generated on-the-fly or can be scheduled to be sent to different recipients. These reports consist of different checks and address various day-to-day DBA tasks. The idea behind ClusterControl operational reporting is to put all of the most relevant data into a single document which can be quickly analyzed in order to get a clear understanding of the status of the databases and its processes.
With ClusterControl you can schedule cross-cluster environment reports like Daily System Report, Package Upgrade Report, Schema Change Report as well as Backups and Availability. These reports will help you to keep your environment secure and operational. You will also see recommendations on how to fix gaps. Reports can be addressed to SysOps, DevOps or even managers who would like to get regular status updates about a given system’s health.
The following is a sample of daily operational report sent to your mailbox in regards to availability:
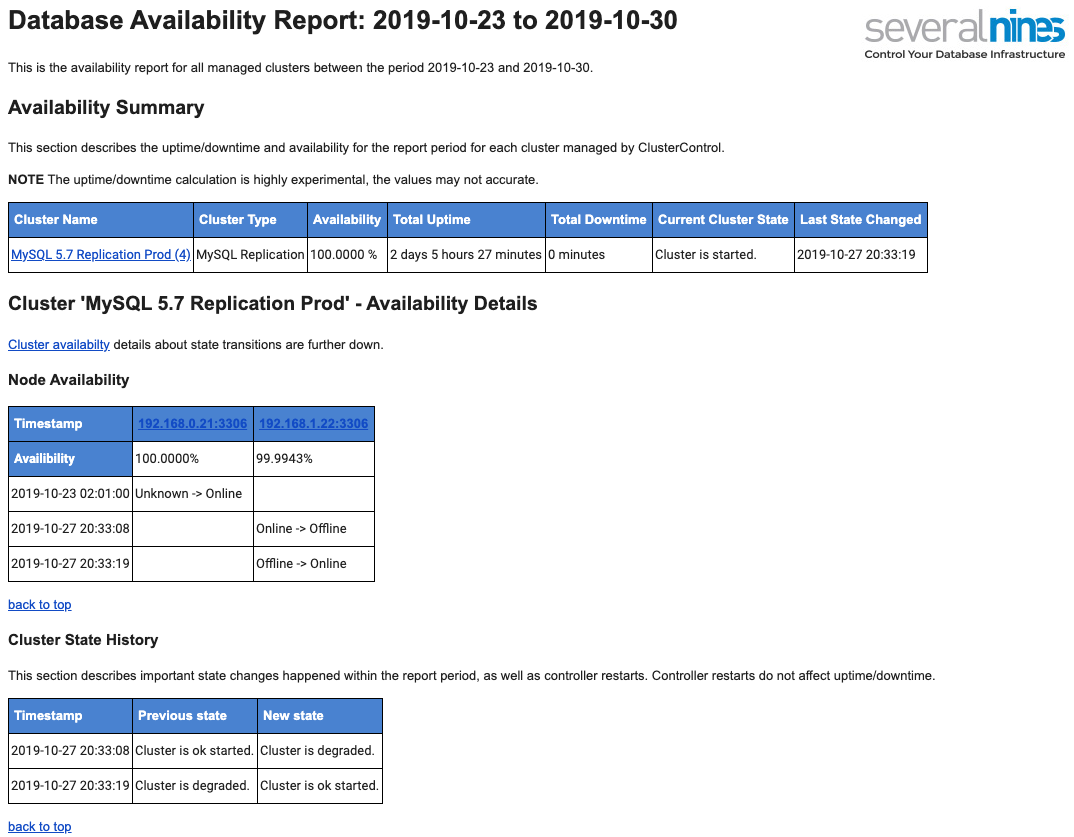
We have covered this in detail in this blog post, An Overview of Database Operational Reporting in ClusterControl.
Resync a Slave via Backup
ClusterControl allows staging a slave (whether a new slave or a broken slave) via the latest full or incremental backup. It doesn't sound very exciting, but this feature is huge if you have large datasets of 100GB and above. Common practice when resyncing a slave is to stream a backup of the current master which will take some time depending on the database size. This will add an additional burden to the master, which may jeopardize the performance of the master.
To resync a slave via backup, pick the slave node under Nodes page and go to Node Actions -> Rebuild Replication Slave -> Rebuild from a backup. Only PITR-compatible backup will be listed in the dropdown:
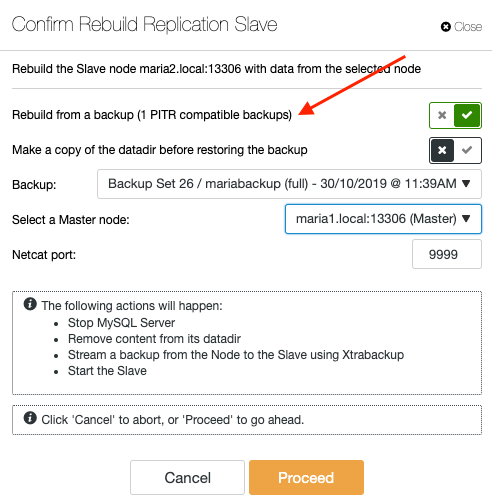
Resyncing a slave from a backup will not bring any additional overhead to the master, where ClusterControl extracts and streams the backup from the backup storage location into the slave and eventually configures the replication link between the slave to the master. The slave will later catch up with the master once the replication link is established. The master is untouched during the whole process, and you can monitor the whole progress under Activity -> Jobs.
Bootstrap a Galera Cluster
Galera Cluster is a very popular when implementing high availability for MySQL or MariaDB, but the wrong management commands can lead to disastrous consequences. Take a look at this blog post on how to bootstrap a Galera Cluster under different conditions. This illustrates that bootstrapping a Galera Cluster has many variables and must be performed with extreme care. Otherwise, you may lose data or cause a split-brain. ClusterControl understands the database topology and knows exactly what to do in order to bootstrap a database cluster properly. To bootstrap a cluster via ClusterControl, click on the Cluster Actions -> Bootstrap Cluster:
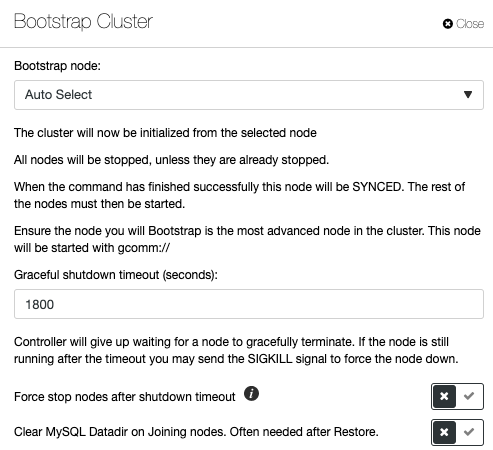
You will have the option to let ClusterControl pick the right bootstrap node automatically, or perform an initial bootstrap where you pick one of the database nodes from the list to become the reference node and wipe out the MySQL datadir on the joiner nodes to force SST from the bootstrapped node. If bootstrapping process fails, ClusterControl will pull the MySQL error log.
If you would like to perform a manual bootstrap, you can also use "Find Most Advanced Node" feature and perform the cluster bootstrap operation on the most advanced node reported by ClusterControl.
Centralized Configuration and Logging
ClusterControl pulls a number of important configuration and logging files and displays them in a tree structure within ClusterControl. A centralized view of these files is key to efficiently understanding and troubleshooting distributed database setups. The traditional way of tailing/grepping these files is long gone with ClusterControl. The following screenshot shows ClusterControl's configuration file manager which listed out all related configuration files for this cluster in one single view (with syntax highlighting, of course):
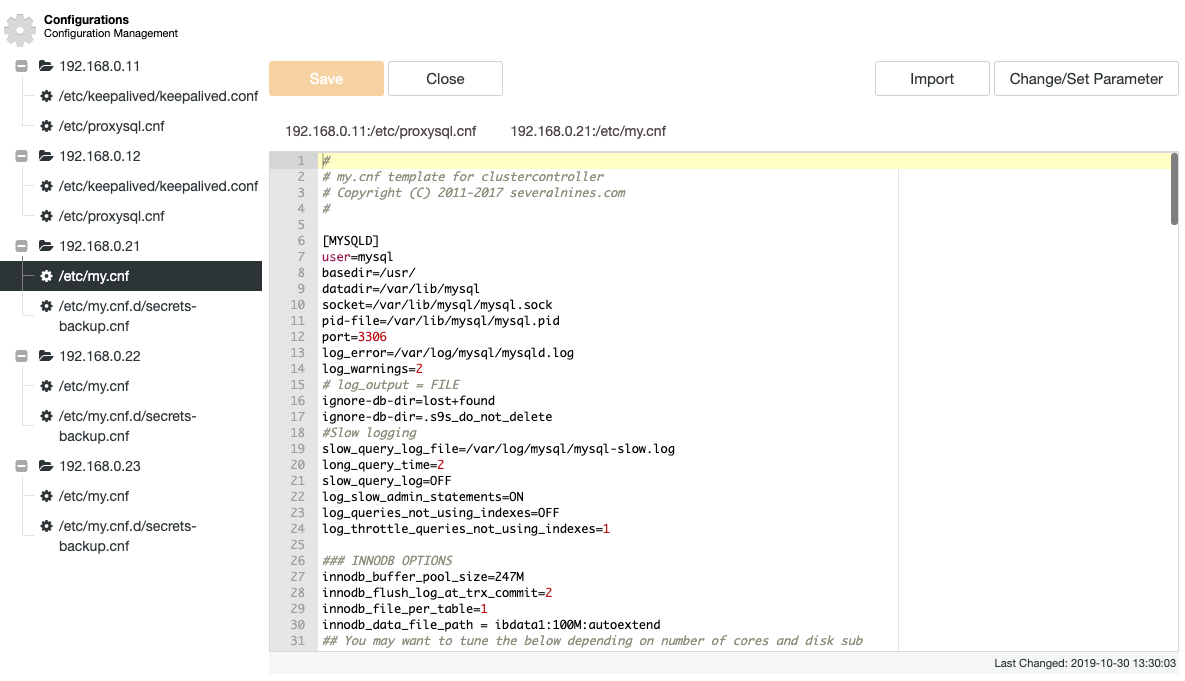
ClusterControl eliminates the repetitiveness when changing a configuration option of a database cluster. Changing a configuration option on multiple nodes can be performed via a single interface and will be applied to the database node accordingly. When you click on "Change/Set Parameter", you can select the database instances that you would want to change and specify the configuration group, parameter and value:
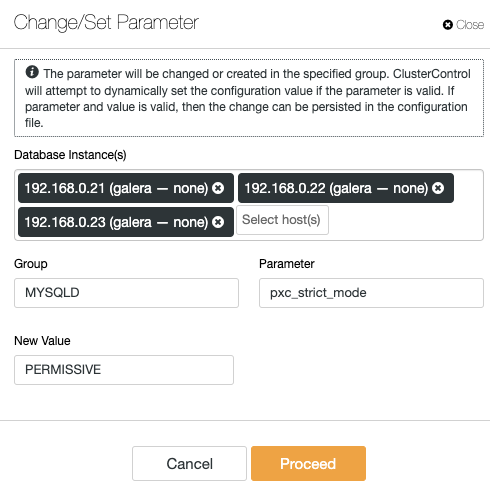
You can add a new parameter into the configuration file or modify an existing parameter. The parameter will be applied to the chosen database nodes' runtime and into the configuration file if the option passes the variable validation process. Some variable might require a server restart, which will then be advised by ClusterControl.
Database Cluster Cloning
With ClusterControl, you can quickly clone an existing MySQL Galera Cluster so you have an exact copy of the dataset on the other cluster. ClusterControl performs the cloning operation online, without any locking or bringing downtime to the existing cluster. It's like a cluster scale out operation except both clusters are independent from each other after the syncing completes. The cloned cluster does not necessarily need to be as the same cluster size as the existing one. We could start with a “one-node cluster”, and scale it out with more database nodes at a later stage.
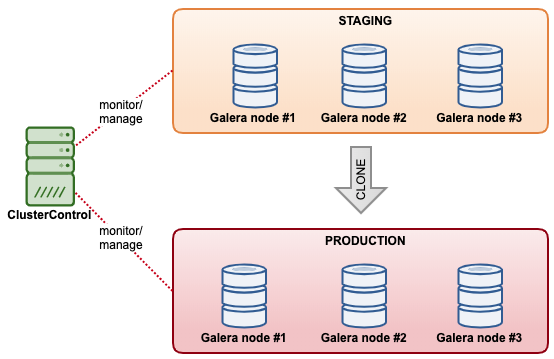
Another similar feature offered by ClusterControl is "Create Cluster from Backup". This feature was introduced in ClusterControl 1.7.1, specifically for Galera Cluster and PostgreSQL clusters where one can create a new cluster from the existing backup. Contrary to cluster cloning, this operation does not bring additional load to the source cluster with the tradeoff that the cloned cluster will not be in the same state as the source cluster.
We have covered this topic in detail in this blog post, How to Create a Clone of Your MySQL or PostgreSQL Database Cluster.
Restore Physical Backup
Most database management tools allow backing up a database, and only a handful of them support database restoration of logical backup only. ClusterControl supports full restoration not only for logical backups, but also physical backups, whether it is a full or incremental backup. Restoring a physical backup requires a number of critical steps (especially incremental backups) which basically involves preparing a backup, copying the prepared data into the data directory, assigning correct permission/ownership and starting up the node in a correct order to maintain data consistency across all members in the cluster. ClusterControl performs all of these operations automatically.
You can also restore a physical backup onto another node that is not part of a cluster. In ClusterControl, the option for this is called "Create Cluster from Backup". You can start with a “one-node cluster” to test out the restoration process on another server or to copy out your database cluster to another location.
ClusterControl also supports restoring an external backup, a backup that has been taken not through ClusterControl. You just need to upload the backup to ClusterControl server and specify the physical path to the backup file when restoring. ClusterControl will take care the rest.
Cluster-to-Cluster Replication
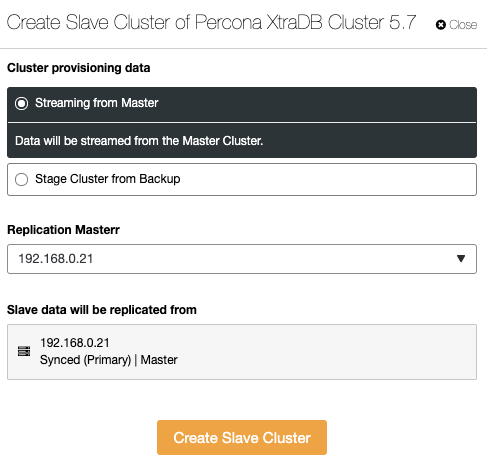
This is a new feature introduced in ClusterControl 1.7.4. ClusterControl can now handle and monitor cluster-cluster replication, which basically extends the asynchronous database replication between multiple cluster sets in multiple geographical locations. A cluster can be set as a master cluster (active cluster which processes reads/writes) and the slave cluster can be set as a read-only cluster (standby cluster which can also processes reads). ClusterControl supports asynchronous cluster-cluster replication for Galera Cluster (binary log must be enabled) and also master-slave replication for PostgreSQL Streaming Replication.
To create a new cluster the replicates from another cluster, go to Cluster Actions -> Create Slave Cluster:
The result of the above deployment is presented clearly on the Database Cluster List dashboard:
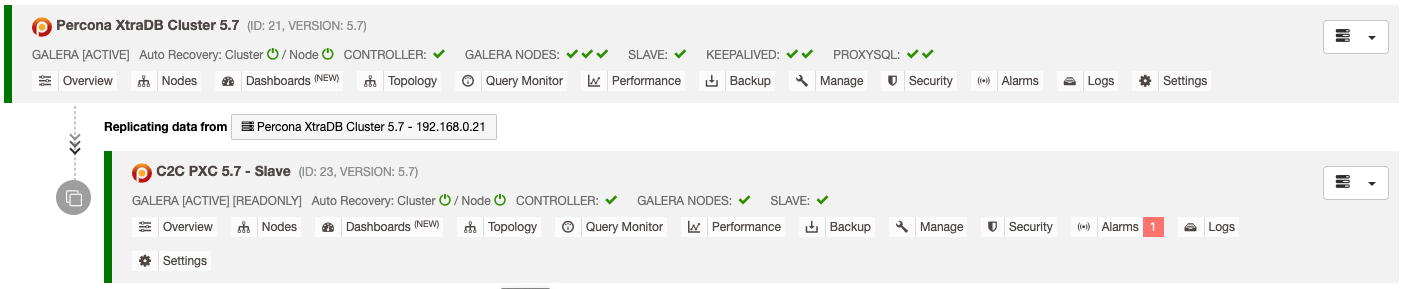
The slave cluster is automatically configured as read-only, replicating from the primary cluster and acting as a standby cluster. If disaster strikes the primary cluster and you want to activate the secondary site, simply pick the "Disable Readonly" menu available under the Nodes -> Node Actions dropdown to promote it as an active cluster.